こんにちは、KIYONOエンジニアです。
本日は、こちらの記事の関連記事として、追加された以下太字のサービスの概要をまとめます。
- データメッシュ関連(Dataplex、Data Catalog)
- Datastream
- Dataform
- Workflows
- Analytics Hub
- BigQuery Omni、BigLake
Google Cloudをこれから学習する方、試験を受ける方の参考になればと思います。
データメッシュとは
概要
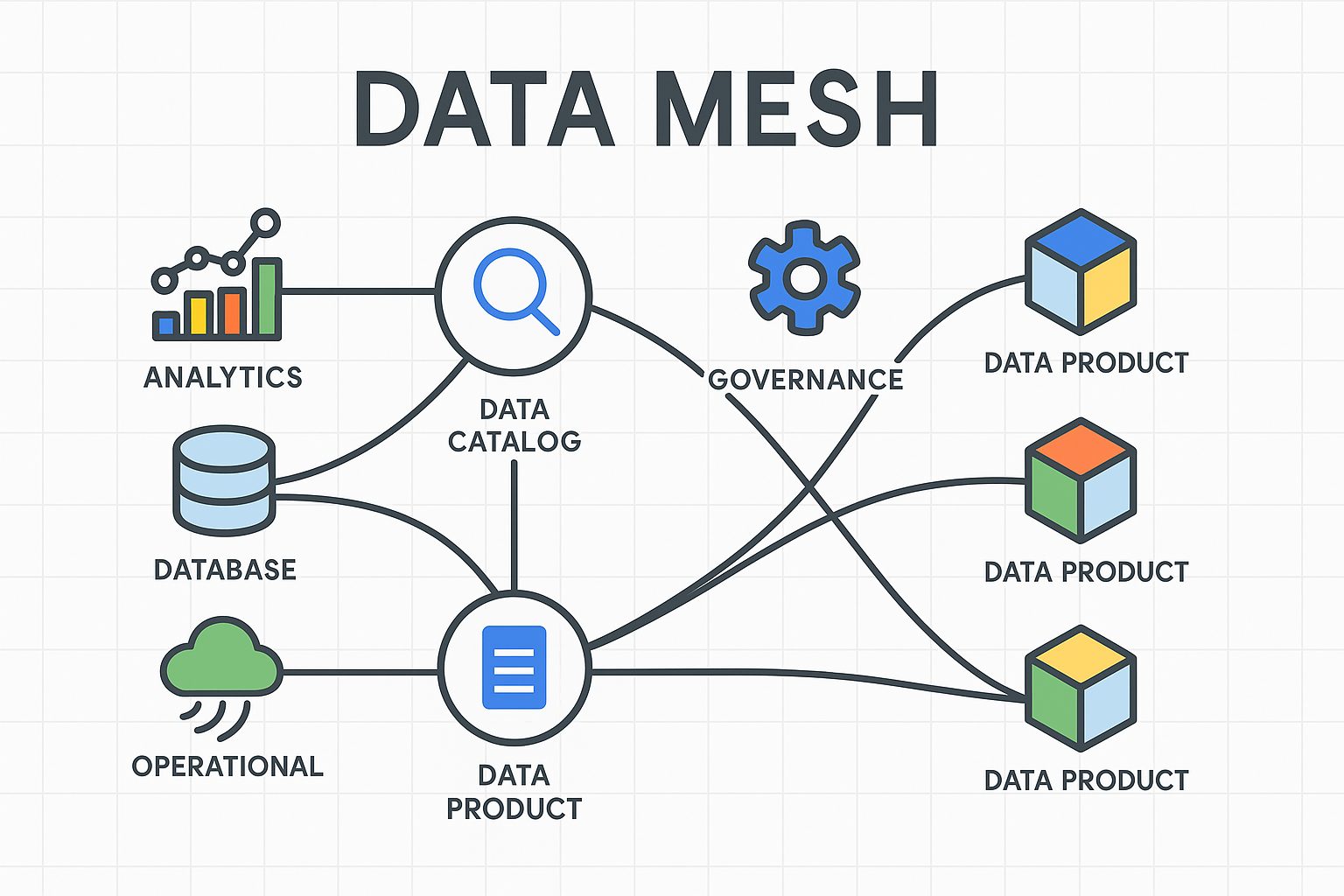
データメッシュとは以下の右側のような状態を指します。
データを一箇所に中央集権的に集約するような左側の状態ではなく、データが分散している状態で管理する、つまり必ずしも一箇所に集める必要はないといった概念になります。注目されている理由として、規模が大きくなればなるほど、「各グループ会社や事業部は既に個別のデータレイクやデータウェアハウス、BIツール環境を持っている」、「データを集約するための開発コストや工数がかかる」、「集約する際の調整が大変」といった課題に直面するため、データメッシュのようなデータが分散した状態で管理するという概念が登場しました。
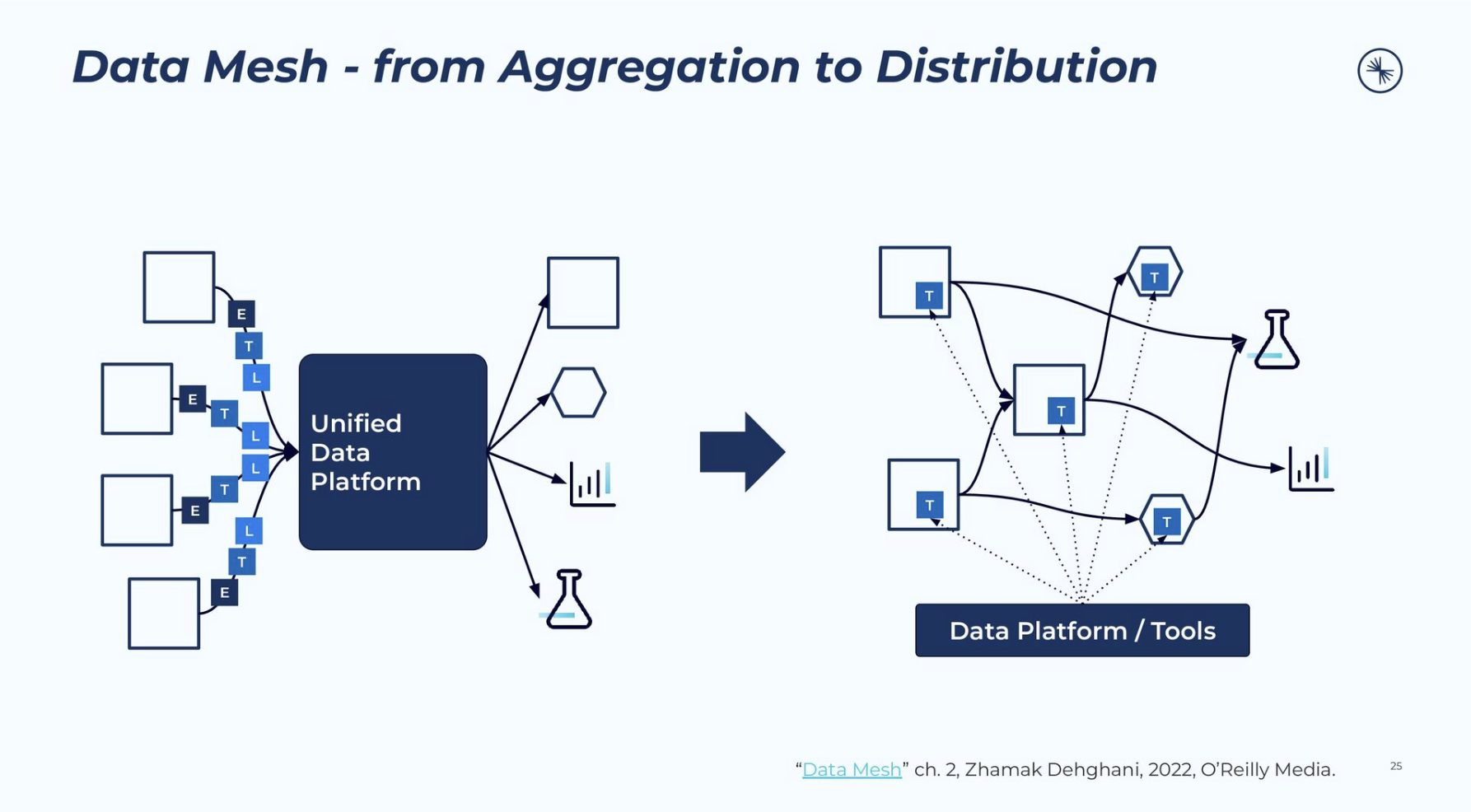
引用元:Developers Summit 2022; Microservices, Data, and Data Mesh; CONFLUENT, Shinichi Hashimoto
Google Cloudの該当サービス
データメッシュを実現するためのGoogle Cloud該当サービスは、Dataplex になります。主な機能は以下の通りです。
| 機能カテゴリ | 説明 |
|---|---|
| メタデータのカタログ化 | BigQuery、Cloud SQL、Spanner、Vertex AI、Pub/Sub、Dataform、Dataproc Metastore などの GCP リソースや、Dataplex にインポートされたサードパーティデータのメタデータを収集し、データアセットのスナップショットを作成します。 |
| データの検出 | Cloud Storage バケット内の構造化・非構造化データを自動的にスキャンし、メタデータを抽出・カタログ化します。 |
| データ分析情報 | AI を活用して自然言語による質問を生成し、パターンの検出、統計分析、データ品質の評価を行います。 |
| データのプロファイリング | BigQuery テーブルの列データについて、代表的な値、分布、NULL 値などを把握し、分類と品質保証の参考情報を提供します。 |
| データ品質 | 組織のポリシーと照らし合わせて BigQuery のデータを検証し、品質基準を満たしていない場合はアラートを記録します。 |
| ビジネス用語集 | ビジネス用語とその定義を組織全体で一元管理し、テーブル列と用語を関連付けて、データの意味を明確にします。 |
| データリネージ | データの流れを可視化し、データがどこから来て、どこへ渡り、どのように変換されたかを追跡可能にします。 |
引用元:Dataplexの概要
画面イメージを上記の表にリンクしているので、ご参考ください。ただしデータの検出は、以下とのことなので割愛します。
2025 年 9 月 30 日までに機能が停止します。Discovery によって公開された BigQuery の外部テーブルは、エントリとして BigQuery ユニバーサル カタログに取り込まれます。Data Catalog から BigQuery ユニバーサル カタログへの移行をご覧ください。
引用元:データを検出します
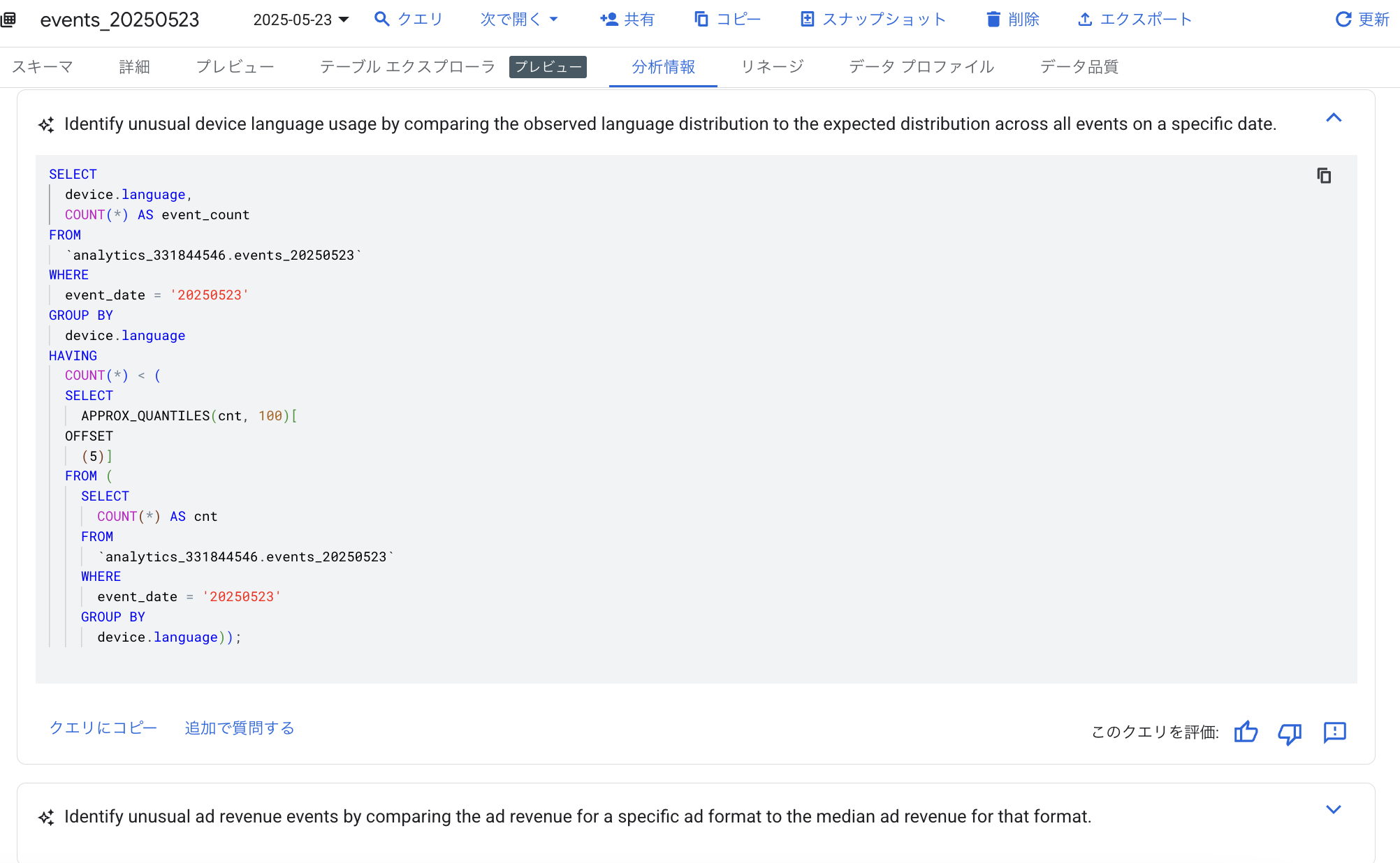
データ分析情報については添付のようにBigQueryにて、分析情報を生成すると集計のパターンとSQLのサンプルを示してもらえます。
Analytics Hub
概要
Analytics Hubとは組織間でデータを効率よく安全に共有可能とする BigQuery を基盤としたデータシェアリング サービスになります。
Analytics Hubにはデータを提供する(Publisher)と、データを活用する(Subscriber)の概念があるのでそれぞれ解説します。

引用元:パブリシャーのワークフロー
Publisherについては上記の通り、一般公開、または限定公開といった形でデータを提供することができます。
またPublisherについてはデータを利用する側(サブスクライバー)に対して、共有されたデータそのものをコピーしたり、自分の環境にダウンロードしたりする行為を禁止・制限するための設定です。これにより、機密性の高いデータをより安全に共有し、意図しない形でのデータの拡散を防ぐことができます。

引用元:サブスクライバーのワークフロー
Subscriberは上図の通りとなります。サブスクライバーが活用したいデータを検索しサブスクライブをするとそのデータが活用できるようになります。データの共有についてはMarketplaceと組み合わせて有料化することも可能です。公式ドキュメント
また 、Analytics Hubにはエクスチェンジとデータクリールームという概念があり、どちらもデータ共有という観点では同じなのですが、データクリーンルームはよりテーブル単位だったりポリシー単位での共有設定が可能となります。
| 特徴 | エクスチェンジ | データクリーンルーム |
|---|---|---|
| 主な目的 | 広範なデータセットの共有と発見 | 機密データの安全な共同分析とプライバシー保護 |
| データアクセス | 権限に基づき、サブスクライバーは共有データセットに直接クエリ可能(生データアクセス可) | 分析ルールに基づき、許可されたクエリのみ実行可能(通常、生データアクセスは不可) |
| 制御レベル | IAMベースのアクセス制御 | IAMに加え、詳細な分析ルールによるクエリ制御、出力制御 |
| プライバシー保護 | 標準的なセキュリティ機能 | プライバシー強化技術の適用を前提とした設計、生データ非開示が基本 |
| 共有単位 | 主にデータセット単位 | データセット内のビュー(分析ルールを適用)単位での制御が中心 |
| 主なユースケース | 部門間データ共有、パートナー連携、公開データ利用、データ販売 | 複数組織間での機密データを用いた共同分析、プライバシーを保護したインサイト共有 |
またAnalytics HubにVPC Service Controlsを適用することも可能となります。
BigQuery Omni、BigLake
概要
まずBigLakeについて説明します。一言で言うとBigLakeは「外部テーブル」と言う意味合いで使われているかと思います。
BigLakeは、BigQueryの外部であるストレージサービスに対してクエリ実行することができます。またAWSのAmazon S3やAzureのBlob Storageに対してはBigQuery Omniを使用して実行することができます。
- Amazon S3(BigQuery Omni を使用)
- Blob Storage(BigQuery Omni を使用)
- Cloud Storage
このようなサービスは、マルチクラウドやデータメッシュの実現を後押しするものと考えられます。
まとめ
いかがだったでしょうか。Google Cloudのサービスの進化の速さには驚きばかりです。3年前に筆者がProfessional Data Engineerを受けた際は、このようなサービスはなかったか、登場したばかりでしたし、気づいたら試験範囲も変わってますし…
同じようにGoogle Cloudをこれから学習する方、試験を受ける方の参考になればと思います。