
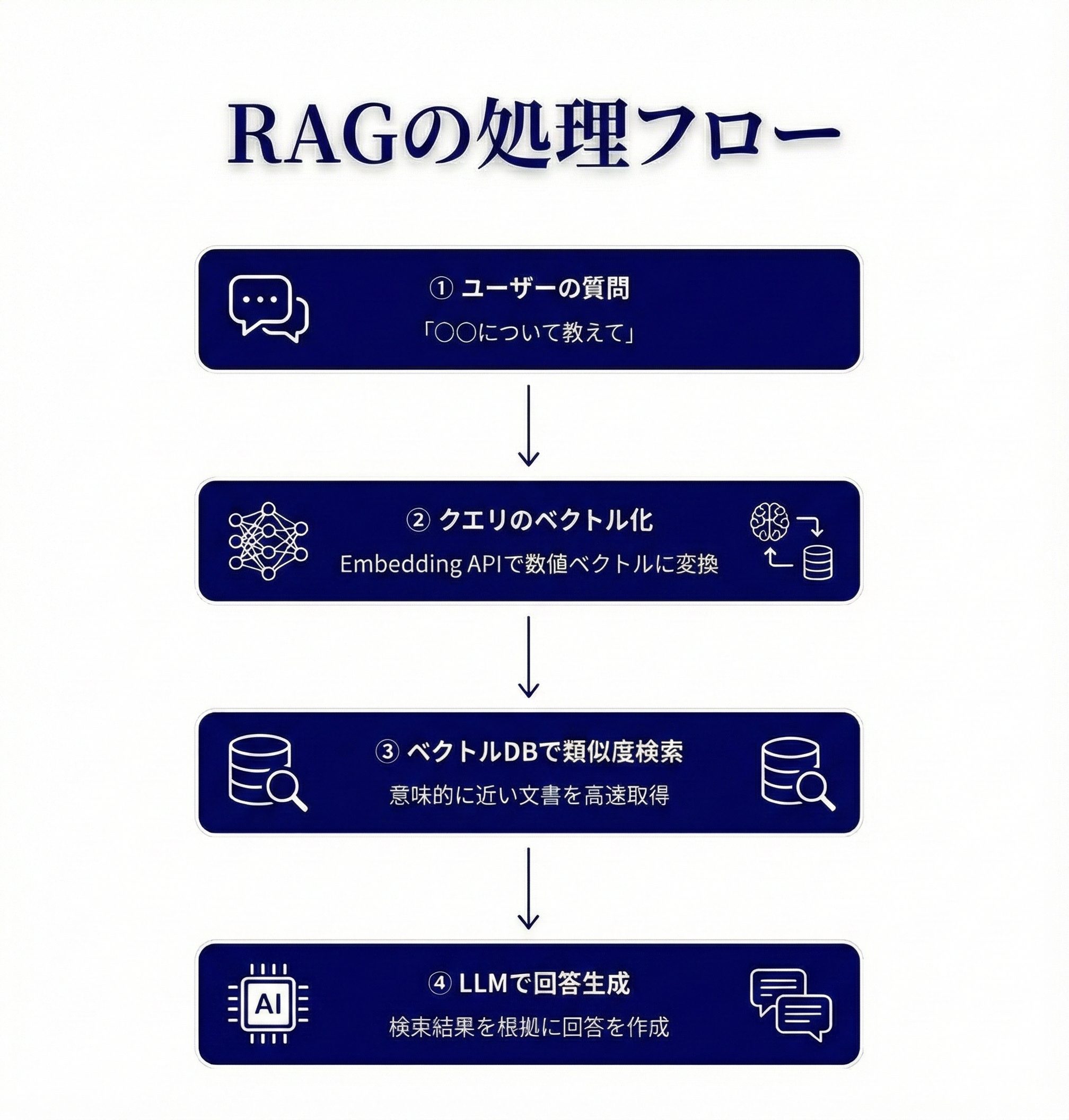
こんにちは、エンジニアの田代です。
ChatGPTをはじめとするLLM(大規模言語モデル)は驚異的な能力を持つ一方で、「学習データに含まれない最新情報や専門的なデータには回答できない」という根本的な課題があります。
この課題を解決するアプローチとして注目されているのがRAG(Retrieval-Augmented Generation:検索拡張生成)です。
本記事では、約40万件の専門記事データベースを対象としたRAGシステムの構築経験をもとに、RAGの基本概念からベクトルDBの仕組み、実装のポイントまでを解説します。
RAGとは何か
RAGは「検索(Retrieval)」と「生成(Generation)」を組み合わせたアーキテクチャです。
ユーザーの質問に対して、まず関連する情報をデータベースから検索し、その情報をコンテキストとしてLLMに渡すことで、根拠に基づいた回答を生成します。
従来のキーワード検索との違い
従来の全文検索では「仏教 歴史」というクエリに対し、これらの単語を含む文書しかヒットしません。
一方、RAGで使用するセマンティック検索では「仏教はいつ頃日本に伝わったのか」という自然言語の質問から、意味的に関連する文書を見つけ出せます。
これが「ベクトル検索」の力です。
RAG vs ファインチューニング:なぜRAGを選ぶのか
LLMを専門分野に対応させる方法として、RAG以外にファインチューニングというアプローチもあります。
両者の違いを理解することで、RAGの利点が明確になります。
| 観点 | ファインチューニング | RAG |
|---|---|---|
| 仕組み | モデル自体を専門データで再学習 | 外部DBを検索して都度参照 |
| データ更新 | 再学習が必要(コスト大) | DBを更新するだけ(容易) |
| 根拠の明示 | 困難(知識がモデルに内包) | 容易(参照元を提示可能) |
| ハルシネーション | 抑制が難しい | 検索結果に限定することで抑制 |
| 初期コスト | 高(GPU、学習時間) | 中(Embedding処理、DB構築) |
今回のプロジェクトでは、40万件の記事が日々更新されるという要件があったため、データ更新の容易さと根拠の明示性を重視してRAGを採用しました。
また、専門分野の情報検索では「なぜその回答になったか」を示せることが重要であり、この点でもRAGが適していました。
ベクトルDB(Vector Database)の仕組み
RAGの中核を担うのがベクトルDBです。
テキストを数値ベクトルに変換し、ベクトル間の類似度で検索を行います。
Embeddingとは
Embeddingとは、テキストを高次元の数値ベクトルに変換する処理です。今回のシステムでは、Vertex AI Embeddingsを使用して768次元のベクトルを生成しています。
ベクトル空間のイメージ
意味的に近い文章は、ベクトル空間上でも近くに配置される
# 概念的なイメージ
"日本の仏教の歴史" → [0.023, -0.156, 0.891, ..., 0.034] # 768次元
"仏教伝来について" → [0.019, -0.148, 0.887, ..., 0.041] # 類似したベクトル
"今日の天気" → [0.567, 0.234, -0.123, ..., 0.789] # 異なるベクトルpgvectorによる実装
今回のシステムでは、PostgreSQLの拡張機能であるpgvectorを採用しました。
専用のベクトルDBを新たに導入するのではなく、既存のRDBMSにベクトル検索機能を追加できる点が大きなメリットです。
-- ベクトルカラムの定義
CREATE TABLE article_vectors (
article_id VARCHAR(50),
chunk_index INTEGER,
content TEXT,
embedding VECTOR(768), -- 768次元ベクトル
PRIMARY KEY (article_id, chunk_index)
);
-- コサイン類似度による検索
SELECT content, 1 - (embedding <=> query_vector) AS similarity
FROM article_vectors
ORDER BY embedding <=> query_vector
LIMIT 10;<=>演算子がコサイン距離を計算し、意味的に近い文書を高速に取得します。
大規模データの前処理:チャンキング
40万件の記事をそのままベクトル化することはできません。
LLMのコンテキストウィンドウには制限があり、また長文のベクトルは検索精度が低下するためです。
そこでチャンキング(文書分割)を行います。
# LangChainによるチャンキング設定
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 1チャンク500文字
chunk_overlap=50, # 50文字のオーバーラップ
separators=["\n\n", "\n", "。", "、", " "]
)500文字という単位は、検索精度と情報の完結性のバランスを考慮した結果です。
オーバーラップを設けることで、文脈が途切れることを防いでいます。
RAGチェーンの構築
検索された文書をLLMに渡し、回答を生成する部分を「RAGチェーン」と呼びます。
プロンプト設計のポイント
RAGにおいてプロンプト設計は極めて重要です。今回のシステムでは以下の原則を設定しました。
- 情報源の厳守:提供された記事の内容のみを使用
- 中立性の保持:特定の立場に偏らない
- 正確性の優先:不確実な情報は提供しない
- 回答できない場合の対応:正直に「情報がありません」と回答
特に重要なのは「ハルシネーション(幻覚)の防止」です。
LLMは学習データから回答を生成しようとする傾向がありますが、RAGでは検索結果のみを根拠とするよう明示的に指示します。
会話履歴の活用
単発の質問応答だけでなく、会話の文脈を考慮した応答も実装しています。
過去の会話履歴をプロンプトに含めることで、「それについてもう少し詳しく」といったフォローアップ質問にも対応できます。
システムアーキテクチャ
本システムは2つのフェーズで構成されています。
システム全体構成
Phase 1:データパイプライン
→
データ取得
→
前処理
→
チャンキング
→
Embedding
→
pgvector
Phase 2:RAGシステム
→
ベクトル検索
→
コンテキスト構築
→
Gemini
→
回答
Phase 1:データパイプライン
- 外部APIからの記事データ取得
- HTMLクレンジング・テキスト正規化
- チャンキング(500文字単位)
- Embeddingベクトル生成
- pgvectorへの保存
Phase 2:RAGシステム
- ユーザー質問の受付
- ベクトル類似度検索(Top-K取得)
- Gemini 1.5 Proによる回答生成
- 会話履歴・フィードバック管理
Cloud Run上でコンテナとして稼働し、Cloud SQLでPostgreSQL + pgvectorを運用しています。
RAGの課題と限界
RAGは強力なアプローチですが、万能ではありません。
実装を通じて見えてきた課題を共有します。
1. 検索精度の限界
ユーザーの質問と文書の表現にギャップがある場合、適切な文書が検索されないことがあります。
例えば、「お寺の建て方」という質問に対して「寺院建築の工法」という文書がヒットしにくいケースです。
この問題に対しては、クエリ拡張やHybrid Search(キーワード検索との併用)などの対策があります。
2. 複数文書の情報統合
回答に必要な情報が複数の文書に分散している場合、LLMがそれらを適切に統合できないことがあります。
特に、矛盾する情報が含まれる場合の処理は困難です。
3.「答えがない」ことの判定
検索結果に関連性の低い文書しかない場合、LLMは無理に回答を生成しようとすることがあります。
類似度スコアの閾値設定や、プロンプトでの明示的な指示により対処していますが、完全な解決は難しい課題です。
4. コンテキストウィンドウの制約
検索結果が多い場合、すべてをLLMに渡すことができません。
重要な文書を優先的に選択するリランキングの仕組みが必要になります。
これらの課題は「RAGの限界」というより「チューニングポイント」と捉えるべきです。Top-Kの数、類似度閾値、チャンクサイズ、プロンプトの指示など、調整可能なパラメータは多く、ドメインに合わせた最適化が品質向上の鍵となります。
RAG実装で得られた知見
検索精度とTop-Kの調整
類似度検索で取得する文書数(Top-K)は、多すぎるとノイズが増え、少なすぎると情報不足になります。
本システムではTop-K=10、類似度閾値0.7を基準として調整しています。
LLMパラメータのチューニング
Geminiのtemperatureパラメータは、創造性と一貫性のトレードオフを制御します。
専門的な情報検索システムでは、正確性を重視してtemperature=0.3〜1.0の範囲で調整を行いました。
トークン制限への対応
検索結果が大量の場合、LLMのトークン上限に達することがあります。
リトライ機能を実装し、トークン上限到達時は検索結果を絞り込んで再試行する仕組みを導入しました。
まとめ
RAGは「LLMの知識を外部データベースで拡張する」という発想で、専門分野における実用的なAIシステムを構築する強力なアプローチです。
- ベクトルDBにより意味的な類似検索が可能に
- チャンキングで大規模データを効率的に処理
- プロンプト設計でハルシネーションを抑制
- pgvectorで既存RDBMSにベクトル検索を追加
- ファインチューニングとの使い分けでコストと柔軟性を両立
一方で、検索精度や情報統合など解決すべき課題もあり、ドメインに応じたチューニングが重要です。
今後、LLMの進化とともにRAGの手法も発展していくでしょう。
特にGraphRAG(知識グラフとの組み合わせ)や、より高度なリランキング手法などが注目されています。