
2026年4月9日の Google Cloud Next ’26 で BigQuery Graph がプレビュー公開され、ISO GQL 標準に準拠したグラフクエリが BigQuery 内でネイティブに実行できるようになりました。本記事では、CDP(カスタマーデータプラットフォーム)の Customer 360・ルックアライク顧客抽出 という業務ユースケースを題材に、プロパティグラフの定義から 類似度検索 との組み合わせまで の実装手順を解説します。Neo4j など外部グラフデータベースからの移行を検討している方にも参考になる内容です。
本記事の対象読者
- CDP・データ基盤を運用しているデータエンジニア/アーキテクト
- Neo4j・TigerGraph 等のグラフデータベースから BigQuery への移行を検討している方
- BigQuery ML・Vertex AI を使った顧客分析の高度化に関心がある方
TL;DR
- BigQuery Graph は2026年4月発表の新機能(プレビュー)。プロパティグラフを BigQuery 内で定義し、GQL(Graph Query Language) でグラフ探索ができる
- 既存の BigQuery テーブルを コピーせずノード・エッジとして再利用 できるため、ETL コストがゼロ
GQL×類似度検索を組み合わせることで、CDP のルックアライク顧客抽出(既存優良顧客に類似する未開拓顧客の発見)を1つの基盤で実装できる- Neo4j・Pinecone・Vertex AI を別契約する従来アーキテクチャから、BigQuery 1基盤への集約が可能になり、TCO 削減効果が大きい
- ただしプレビュー段階のため、ミッションクリティカルな本番運用は GA を待つのが安全
BigQuery Graph とは:2026年プレビュー公開の新機能
BigQuery Graph は、Google Cloud がデータウェアハウスの BigQuery にネイティブで追加した プロパティグラフ機能 です。2026年4月9日に Google Cloud Next ’26 で正式発表され、現在 Pre-GA(プレビュー)で提供されています。
特徴は以下の通りです。
- ISO GQL 標準準拠:Graph Query Language(GQL)は ISO で標準化されたグラフクエリ言語で、Cypher に似た構文を持つ
- SQL/PGQ 標準にも対応:標準 SQL と GQL を同一クエリ内で組み合わせ可能(
GRAPH_TABLE演算子) - データ移動が不要:既存の BigQuery テーブルをそのままノード・エッジとして指定するだけ
- BigQuery Studio で可視化:Notebook 上で
%%bigquery --graphマジックコマンドにより、グラフ構造を即座に可視化可能
従来は Neo4j・TigerGraph・Amazon Neptune といった専用のグラフデータベースに ETL してから分析する必要がありました。BigQuery Graph により、データウェアハウス上でグラフ分析が完結するようになります。
BigQuery Graph の主なユースケース:CDP・Customer 360・不正検知
Google Cloud 公式の Codelab でも以下の3つが代表ユースケースとして紹介されています。
- Customer 360・レコメンデーション(小売・EC)
- 不正検知(Fraud Detection)(金融・決済)
- サプライチェーン分析(製造)
本記事では特に CDP におけるルックアライク顧客抽出 にフォーカスします。
CDP におけるグラフ分析の価値
オムニチャネル CDP では、通常以下の3種類のデータを統合します。
| データレイヤー | 主な項目 | 結合キー |
|---|---|---|
| 会員マスタ | 会員ID、属性、会員ランク | member_id |
| 取引データ(POS / EC) | 取引ID、商品コード、決済情報 | member_id, product_id |
| Web 行動ログ(GA4) | PV、カート投入、流入経路 | user_id(= member_id) |
従来の SQL では、これらを member_id で JOIN して特徴量テーブルを作るのが定石でした。しかし「顧客 → 商品 → 別の顧客」のような 2ホップ以上のカスタマージャーニー を SQL で表現すると、JOIN が複雑化してパフォーマンスとメンテナビリティが悪化します。
BigQuery Graph を使えば、この ネットワーク構造 をそのままクエリで表現でき、ルックアライク顧客抽出・併売分析・離反予兆検知などの実装が大幅に簡略化されます。
BigQuery Graph の実装手順:CDP のルックアライク顧客抽出
ここからは実際に BigQuery Graph と VECTOR_SEARCH を組み合わせ、CDP のルックアライク顧客抽出を実装する手順を解説します。
Step 1:プロパティグラフを定義する(CREATE PROPERTY GRAPH)
既存の BigQuery テーブル(Members、Products、GA4_Web_Events、POS_Transactions)を、ノードとエッジとしてマッピングします。
CREATE OR REPLACE PROPERTY GRAPH `cdp.Customer360Graph`
NODE TABLES (
`cdp.Members` KEY(member_id) LABEL Customer,
`cdp.Products` KEY(product_id) LABEL Product
)
EDGE TABLES (
`cdp.GA4_Viewed_Edges`
KEY (event_id)
SOURCE KEY (user_id) REFERENCES `cdp.Members` (member_id)
DESTINATION KEY (product_id) REFERENCES `cdp.Products` (product_id)
LABEL Viewed,
`cdp.POS_Transactions`
KEY (transaction_id, product_id)
SOURCE KEY (member_id) REFERENCES `cdp.Members` (member_id)
DESTINATION KEY (product_id) REFERENCES `cdp.Products` (product_id)
LABEL Purchased
);
ポイントは 既存テーブルをそのままエッジ・ノードの定義に再利用 できる点です。データのコピーや再構造化は不要で、PROPERTY GRAPH はメタ定義(論理ビュー)として機能します。
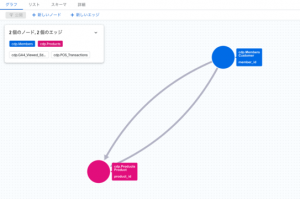
作成すると以下の図のように(Customer)と(Transaction)が[View]と[Purchased]の矢印で結ばれたGraphが確認できます。
Step 2:GQL でルックアライク顧客を抽出する(MATCH 構文)
「特定カテゴリの商品を Web 閲覧したが未購入の顧客」と「同じ商品を購入した既存顧客」のネットワーク関係を、GQL の MATCH 句で表現します。
GRAPH cdp.Customer360Graph
MATCH
(target:Customer)-[v:Viewed]->(p:Product)
<-[purc:Purchased]-(lookalike:Customer)
WHERE p.category = '湿気対策'
FILTER NOT EXISTS {
MATCH (sub_target:Customer)-[:Purchased]->(sub_p:Product)
WHERE sub_target = target AND sub_p = p
}
RETURN
target.member_id AS target_user,
lookalike.member_id AS successful_user,
p.product_id AS bridge_product,
COALESCE(purc.transaction_date, v.event_timestamp) as event_timestamp
;
注意点:GQL のサブクエリは標準 SQL とは異なり 波括弧 {} で囲みます。NOT EXISTS (...) と書くと構文エラーになります。Cypher 経験者には馴染みやすい構文ですが、SQL エンジニアは慣れが必要です。
Step 3:ベクトル類似度計算(ML.DISTANCE / VECTOR_SEARCH)で補完する
GQL は構造的な関係性の抽出が得意ですが、「セッション時間」「ページ遷移パターン」など連続値の類似度は扱えません。ここを補うのが BigQuery の機械学習関数です。
グラフ探索ですでにターゲット候補が数百〜数千人規模に絞り込めている場合は、総当たりの距離計算を行う ML.DISTANCE を使うのが、最もシンプルでパフォーマンスも安定するベストプラクティスです。
例えばここではランクの高い女性の活動サマリーの文章から類似したユーザーを探索するクエリを作ってみましょう。
WITH
-- Step 1: GQLで湿気対策のルックアライク候補を抽出
lookalike_candidates AS (
SELECT DISTINCT v.target_user AS member_id
FROM GRAPH_TABLE(
`cdp.Customer360Graph`
MATCH (target:Customer)-[:Viewed]->(p:Product)<-[:Purchased]-(lookalike:Customer)
WHERE p.category = '湿気対策'
COLUMNS (target.member_id AS target_user, p.product_id AS product_id) ) AS v
WHERE NOT EXISTS (
SELECT 1 FROM GRAPH_TABLE(`cdp.Customer360Graph`
MATCH (c2:Customer)-[:Purchased]->(p2:Product)
COLUMNS (c2.member_id AS member_id, p2.product_id AS product_id)
) AS pur
WHERE v.target_user = pur.member_id AND v.product_id = pur.product_id
)
),
-- Step 2: 候補の embedding を取得
candidate_vectors AS (
SELECT e.member_id, e.customer_vector, e.behavior_summary
FROM `cdp.Embedded_Customers` e
JOIN lookalike_candidates c ON e.member_id = c.member_id
),
-- Step 3: ターゲットユーザー(M0001)のベクトルを取得
target_vector AS (
SELECT customer_vector AS target_vec
FROM `cdp.Embedded_Customers`
WHERE member_id = 'M0001'
)
-- Step 4: ML.DISTANCE で距離計算 (候補が絞られているため CROSS JOIN でも高速)
SELECT
c.member_id,
c.behavior_summary,
-- customer_vector.result (ARRAY) 同士のコサイン距離を計算
ML.DISTANCE(c.customer_vector.result, t.target_vec.result, 'COSINE') AS distance
FROM candidate_vectors c
CROSS JOIN target_vector t
ORDER BY distance ASC
LIMIT 10;
顧客の行動ベクトルは AI.GENERATE_EMBEDDING 関数(旧 ML.GENERATE_TEXT_EMBEDDING)で生成できます。Vertex AI の text-embedding 系モデルを BigQuery のリモートモデルとして登録すれば、SQL からシームレスに呼び出せます。
※embeddingを自律的に生成するやり方もあるのでまた別の記事でご紹介します。
公式:自律的エンべディング生成
💡 応用:VECTOR_SEARCH との使い分け
もし、「GQLで絞り込んでも数十万人以上の候補が残る」ような大規模なデータセットの場合は、BigQuery の VECTOR_SEARCH 関数 とベクトルインデックス(CREATE VECTOR INDEX)を組み合わせて使うアプローチに切り替えます。
VECTOR_SEARCH は、インデックスを活用した近似近傍探索(ANN)により、数千万件のデータからでもミリ秒単位で類似顧客を抽出することが可能です。
実運用では以下の「2段構え」の使い分けが効果的です。
- GQL でグラフ探索 → 商品・カテゴリ単位で候補を絞り込み(数千件なら
ML.DISTANCEで正確に再ランキング) - VECTOR_SEARCH で大規模探索 → グラフ構造に縛られず、全顧客から純粋な「行動の類似性」だけで高速にピックアップ
「構造的類似性(グラフ)× 行動類似性(ベクトル)」の組み合わせが、BigQuery の AI 機能群を 1 つの基盤に集約する最大の価値です。
BigQuery Graph 実装時の注意点・つまずきポイント
実際に検証してわかった3つの注意点を共有します。
1. ベクトルインデックスがフルスキャンに落ちる閾値がある
CREATE VECTOR INDEX を作成しても、データ件数が少ないと内部的にフルスキャンに切り替わります。数千行のサンプルでは性能評価が本番と乖離するため、最低でも数万行〜数十万行のテストデータで検証することを推奨します。
2. プレビュー機能であることの説明責任
BigQuery Graph は Pre-GA であり、Google Cloud の “Pre-GA Offerings Terms” の対象です。SLA・仕様変更の可能性があるため、エンタープライズ案件では まず分析・PoC 用途に限定 し、ミッションクリティカルな本番フローに組み込むのは GA を待つのが無難です。
3. ID レゾリューション(名寄せ)は別問題として残る
GA4 の Cookie ID と POS の会員 ID の突合といった ID 名寄せ は、BigQuery Graph では自動化されません。Dataform / dbt での前処理パイプラインで解決する必要があります。BigQuery Graph はあくまで「すでに統合された ID 上でのネットワーク分析」を担当する機能と整理してください。
BigQuery Graph 導入による CDP アーキテクチャの変化:Neo4j からの移行
BigQuery Graph の登場により、エンタープライズ CDP のアーキテクチャは大きく変わる可能性があります。
Before:マルチプロダクト構成
BigQuery (DWH)
├─ ETL → Neo4j(グラフ分析)
├─ ETL → Pinecone / Weaviate(ベクトル検索)
└─ ETL → Vertex AI(LLM 推論)
After:BigQuery 集約構成
BigQuery
├─ プロパティグラフ(GQL)
├─ VECTOR_SEARCH(ベクトル検索)
└─ AI.GENERATE_TEXT / AI.GENERATE_EMBEDDING(LLM 推論)
Neo4j から BigQuery Graph に移行するメリット
- ETL パイプラインの削減:データ移動が不要になるため、保守工数が削減
- ライセンス費の削減:Neo4j Enterprise のライセンス費用が不要
- クエリ統合:標準 SQL と GQL を同一クエリで記述可能(
GRAPH_TABLE演算子) - 権限管理の統合:BigQuery の IAM・列レベルセキュリティで一元管理
ただし Cypher で書かれた既存クエリの GQL への書き換え工数、グラフアルゴリズム(PageRank、Community Detection など)の機能差については個別検証が必要です。
まとめ:BigQuery Graph で CDP の内製化は可能か
BigQuery Graph はまだプレビュー段階ですが、「BigQuery 1基盤でグラフ × ベクトル × AI を完結させる」というアーキテクチャは、CDP・Customer 360 の次のスタンダードになり得ます。GA 公開を待ってから検討するより、いまの段階で社内 PoC に着手しておくと、来期の予算策定・体制設計に間に合います。
特に以下に該当する企業は、早期検証の価値が高いです。
- すでに BigQuery で CDP・データ基盤を構築済み
- Neo4j・TigerGraph 等のグラフ DB を導入したがコスト・運用負荷が課題
- ベクトル検索基盤を別途構築しており、ライセンス費を削減したい
- LLM・RAG を活用した顧客分析を内製化したい
よくある質問(FAQ)
Q. BigQuery Graph は GA ですか?
A. 2026年5月時点では Pre-GA(プレビュー)です。Google Cloud Next ’26 で発表され、利用は可能ですが SLA・仕様変更の対象となります。
Q. BigQuery Graph の料金はどうなりますか?
A. プロパティグラフの作成自体に追加料金はなく、通常の BigQuery クエリ料金(オンデマンドまたはエディション課金)が適用されます。ただし利用にはBigQuery Graph を使用するには、
Enterprise エディションまたは Enterprise Plus エディションを使用する 予約が必要です。 グラフクエリでは、 スロットで測定される BigQuery 容量コンピューティングの料金 が使用されます。
とのことですので現在のご契約状況はご確認が必要になります。
Q. Neo4j から BigQuery Graph に移行できますか?
A. データ移行・スキーマ変換は可能ですが、Cypher で書かれた既存クエリは GQL への書き換えが必要です。両者は ISO GQL 標準のもとで構文が近く、移行コストは比較的小さいです。
Q. GQL は SQL と何が違いますか?
A. GQL はグラフパターンマッチングに特化した言語で、ノードを ()、エッジを []、関係の方向を -> で表現します。ISO で標準化されており、Cypher に類似した構文です。標準 SQL と組み合わせて使うことも可能です。
Q. LlamaIndex や LangChain と連携できますか?
A. BigQuery の VECTOR_SEARCH 部分は LangChain(BigQueryVectorStore)・LlamaIndex(BigQueryVectorStore)から利用可能です。GQL 部分は現状直接の統合がないため、SQL/GQL クエリ結果をリトリーバに渡す形で連携します。
関連用語
- プロパティグラフ:ノードとエッジに任意のキー・バリュー属性を持たせるグラフモデル
- GQL(Graph Query Language):ISO 標準のグラフクエリ言語
- SQL/PGQ:標準 SQL の中でグラフパターンマッチングを行うための ISO 標準拡張
- VECTOR_SEARCH:BigQuery のベクトル類似度検索関数
- AI.GENERATE_EMBEDDING:Vertex AI のリモートモデルを使った embedding 生成関数
- Customer 360:顧客に関するあらゆるデータを統合した360度ビュー
- ルックアライク:既存の優良顧客に類似する未開拓顧客を抽出する手法
株式会社KIYONOからのお知らせ
弊社は GCP・BigQuery を中心とした CDP・顧客カルテ・データ基盤構築 を専門とする Google Cloud パートナーです。金融・通信・小売・出版領域のエンタープライズ企業を中心に、以下のサービスを提供しています。
- BigQuery Graph × CDP の PoC 支援:プレビュー段階の機能を貴社データで検証
- Neo4j・TigerGraph からの移行設計:既存グラフ DB から BigQuery への移行ロードマップ策定
- Dataform / dbt による embedding パイプライン構築:
AI.GENERATE_EMBEDDINGの自動運用化 - 顧客カルテ・ルックアライク分析の実装:BigQuery ネイティブの顧客分析基盤の構築
「BigQuery Graph をうちの CDP で試したい」「Neo4j からの移行を検討している」といったご相談を歓迎します。