
こんにちは。エンジニアの平田です。
今回は、GA4の行動データを使って、行動パターンに応じた顧客分類を行ってみたいと思います。こちらの記事では「GA4のデータを使って訪問ユーザーのアクセスページパターンを分析し、訪問回数が多い人はどんな記事を閲覧しているか?」を題材としております。
対象者
マーケター/分析者

以下を調べている方
- 自社のサイトに来る人はどういう使い方をしているのか?
- リテンションレートの高い人たちはどういった使い方をしているか
※この記事はエンジニア向けになります。作成された分類を使った分析については次回の記事をご参照ください。
次回→ BQMLを使って顧客分類をやってみた【マーケター編】
エンジニア
 こんな方はご参考ください。
こんな方はご参考ください。
- BigQuery MLを使ってみたいけどどういった準備をすればいいかわからない
- なんとなく使うのが億劫だ
本記事のゴール
本記事ではBigQuery ML (以降、BQMLと呼称) を使うところにフォーカスして紹介したいと思います。
マーケターの方はこちらの【GA4・BQML】BQMLを使って顧客分類をやってみた(マーケター編)をご覧ください。
目次
- 前提知識の紹介
- GA4の行動データ
- BQML
- KMEANS
- エンジニア目線での操作方法
- 改めて題材の目的確認
- BigQueryでのテーブル作成
- BQMLのKMEANSによる分類
前提知識
GA4の行動データ
GA4の行動データとは、ユーザーのWebサイトやアプリの利用状況を記録したデータです。このデータには、ページビュー数、セッション数、滞在時間などの情報が含まれています。余談ですが、GA4の生データは無料でBigQueryに出力することができます。
BQML
BQMLとは、BigQueryで利用できる機械学習の機能です。BQML を使用すると、Google SQL クエリを使用して機械学習モデルを作成して実行できます。BQML は、SQL 実務担当者が既存の SQL ツールやスキルを使ってモデルを構築することを可能にし、機械学習 をより多くの人が利用できるようにします。
KMEANS
KMEANSとは、クラスタリングと呼ばれる手法の一種で、データの特徴を元に似たようなデータをグループ分けする手法です。
所謂教師無し学習に分類される手法です。あらかじめテストデータを作成する必要はなく、持っているデータを与えることでいくつかのデータに自動的に分類してくれます。
エンジニア目線での操作方法
改めて題材の目的確認
今回の記事では「GA4のデータを使った訪問ユーザーのアクセスページパターンを分析すること」をゴールとしています。
1ユーザーがこれまで訪問したページのPV数を集計し、どんなページを閲覧する傾向にあるのかを調べたいと思います。
データ準備
機械学習を始めて行う方にとって意外と難しいのが「そもそもどういった形でデータを作成すれば良いか」なのかなと思います。
機械学習のモデルによってモデル作成に使用するデータの構造は様々ですが、今回の題材で扱うKMENASについては、1行1単位で集計されたデータを使用します。
もしユーザーのクラスタリングを行う場合は1行1ユーザーですし、セッションのクラスタリングをしたい場合は1行1セッションとなります。
今回はユーザーの特徴に応じた分類を行いたいので、1行1ユーザーの形で特定期間内のページごとのPV数を集計したいと思います。
最終的に以下のようなテーブルを作成します。
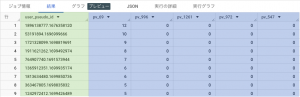
緑色の部分が集計の軸(ディメンション)で、青色の部分が集計値(指標)です。
今回の集計では以下のデータを使用しました。
ディメンション… user_pseudo_id (GA4でのブラウザに一意なID)
指標… ページパスごとのPV数
モデルの作成
先ほど作成したデータを使ってKMEANSのモデルを作成しましょう。
CREATE OR REPLACE MODEL `PROJECT.DATASET.MODEL_NAME`
OPTIONS (
MODEL_TYPE ="KMEANS", -- (必須) モデルのタイプ。
NUM_CLUSTERS = 5 -- (オプション)クラスタサイズ。自由に調整可能です。
) as
SELECT
*EXCEPT(user_pseudo_id) -- 分類に使用するカラムだけを指定する。
FROM `先ほど作成したテーブル`クラスタサイズとは、最終的に何個に分類するかのパラメータです。num_clusters オプションを省略すると、トレーニング データの総行数に基づき適切なデフォルト値が BigQuery ML によって選択されます。
クエリを実行するとモデルが作成されます。
![]()
モデルの確認
作成されたモデルを確認してみましょう。
管理画面上からでも確認できますが、すべての特徴を確認できるわけではありません。
特徴を確認するためには以下のクエリを実行し、Looker Studioで可視化させます。
SELECT * FROM ML.centroids(MODEL `作成されたモデル`, STRUCT(TRUE AS standardize))Looker Studioでピボットテーブルを選択し、下の写真のように設定することでクラスタごとの指標の特徴の大きさを可視化できます。
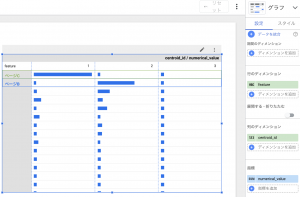
centroid_id… クラスタのID。
feature… 特徴の名前。
numerical_value… 量的変数の特徴量。
なんだかクラスタごとに特徴が違うみたいですね。
クラスタリングはできたみたいなので、次回はクラスタごとの行動の違いを深掘っていきましょう。
まとめ
今回の記事ではBQMLを使った顧客分類の第一弾として、
- データ作成
- モデル作成
- 特徴の可視化
を行いました。
GA4の行動データを使えば行動パターンに応じた顧客分類を実行でき、顧客理解を深めたり、マーケティング施策の改善に役立てることができます。
次回の記事では顧客分類を使用した分析について解説しようと思います。
次回→ BQMLを使って顧客分類をやってみた【マーケター編】
終わりに
2022年にUAからGA4に移行され、お客様からGA4のデータを使ったマーケティング支援をお求めいただく機会が増えてきました。
GA4では無料でデータを出力する機能があります。まだGA4を十分に使えていない方、ある程度GA4を使っているけれどこれといった分析ができていないと感じる方はぜひ我々にご相談ください。