
暑くなってきました。KIYONOエンジニアの平田です。
今回は、GCPのWorkflowsを使ってBigQueryを操作する作業について皆さんに共有したいと思います。
対象者
- Workflowsを初めて使う方
- 一連の処理を自動化したい方
Workflowsとは
Workflowsについて、公式ドキュメントでは以下のように紹介されています。
ワークフローは、フルマネージドのオーケストレーション プラットフォームで、定義した順序(ワークフロー)でサービスを実行します。これらのワークフローでは、Cloud Run や Cloud Functions でホストされているカスタム サービス、Cloud Vision AI や BigQuery などの Google Cloud サービス、任意の HTTP ベースの API を含むサービスを組み合わせることができます。
なるほど。HTTPベースのAPIを順序立てて実行できるサービスのようですね。
ossのワークフローエンジンではdigdagやargo workflowsなどを利用されるケースが多いかと思いますが、これらのアプリケーションを自前で運用するとなるとサーバー構築から定期的なメンテナンスなどの運用コストや、アプリケーションの学習コストがかかります。GCPにはCloud ComposerというAirflowのマネージドサービスも存在していますが、サーバーレスではないため維持コストがそこそこかかります(Cloud Composer料金について)。Workflowsを利用することで前述のコストを低減することが期待できます。サーバーレスで稼働した分しか料金を請求されないのもコスト節約の面から魅力的ですね。一方で複雑なワークフローを作成したりリッチなUIで操作することはできないのでこの点は一長一短といったところでしょうか。
複数のサービスを組み合わせられるとなると、
- GCSのCSVファイルをBiqQueryへロード→加工→SpreadSheetへ出力
- Google Adsレポートデータの取得→予算と実績の確認→確認内容をSlack通知
等の一連の作業を自動化できます。
なお、本記事ではWorkflowsを使って処理を実行するところに焦点を当てておりますが、WorkflowsにはEventarcと組み合わせることでGCPサービスのイベントをトリガーに処理を開始できるという強みもあります(Eventarcに関する公式ドキュメント)。イベントドリブンな設計を取りながら疎結合なサービス間連携を可能とする個人的に興味深い組み合わせです。時間があるときにこちらも記事にしていきたいと思います。
WorkflowsでBigQueryを操作する
1. 全体構成
今回は練習としてRecency, Frequency, Monetaryの情報が付与されたユーザー一覧テーブルを作成してみましょう。
構成は以下のようになります。
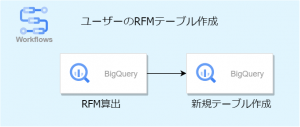
サンプルデータは以下のカラム構成となっております。
| フィールド名 | 種類 | 説明 |
| invoice_number | STRING | 注文ID |
| stock_code | STRING | 商品ID |
| unit_price | STRING | 単価 |
| quantity | INTEGER | 数量 |
| sales | INTEGER | 売上合計 |
| customer_id | STRING | 顧客ID |
| invoice_date | TIMESTAMP | 取引日時 |
2. 新規ワークフロー作成
公式ドキュメントに従ってワークフロー名、リージョン、サービスアカウントの設定まで行います。
サービスアカウントにはBigQueryのジョブ作成のための権限を付与してください。
3. 定義ファイルの作成
以下の要領でワークフローを作成します。
main:
steps:
- init:
assign:
# 変数を作成する
- from_: 2021-01-01
- to_: 2021-04-01
- dataset: {{ YOUR_DATASET }} # 使用するデータセット名を入れる
- table: {{ YOUR_TABLE }} # 使用するテーブル名を入れる
- target: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID") + "." + dataset + "." + table}
- selectStatement: ${"SELECT customer_id, DATE_DIFF(MAX(invoice_date), TIMESTAMP '" + to_ + "', DAY) AS recency, SUM(sales) AS monetary, COUNT(DISTINCT invoice_number) AS frequency FROM `" + target + "`"}
- whereStatement: ${"WHERE DATE(invoice_date) BETWEEN '" + from_ +"' AND '" + to_ + "'"}
- groupbyStatement: "GROUP BY customer_id"
# BigQueryにクエリを投げる
- create_users_rfm:
call: googleapis.bigquery.v2.jobs.query
args:
projectId: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")}
body:
query: ${selectStatement + " " + whereStatement + " " + groupbyStatement}
useLegacySql: false
defaultDataset:
datasetId: ${dataset}
projectId: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")}
destinationTable: users_rfm
result: queryResult
# 確認のためクエリ結果を含めたログを返す
- return_result:
return: ${queryResult}ここでのポイントは以下の3点です
- 変数の作成
- 環境変数取得をする
- 変数への格納
①. 変数の作成
Workflowsでは、変数は${}で囲って作成します。また、変数を宣言するためにはassign: を作成しリスト型のKey: Value構造で変数を設定します。
変数の作成に関する詳細は公式ドキュメントにも記載されていますので是非ご覧ください。変数の例や、スコープについての解説が載っています。
②. 環境変数を取得する
Workflowsを実行しているプロジェクト名や、ワークフローのIDなどが取得できます。
③. 変数への格納
APIへリクエストした後のレスポンスはresultで回収することができます。
レスポンス結果に応じて処理を分岐させたり、次のステップに値を渡したりする際に重要な処理となります。
4. レスポンスの確認
さて、ワークフローを実行して最終的な出力を確認してみましょう。
今回作成したWorkflowではgoogleapis.bigquery.v2.jobs.queryへのリクエスト結果全文を出力するように設定しました。
出力結果を確認してみましょう。
{
"cacheHit": true,
"jobComplete": true,
"jobReference": {
"jobId": "job_JZrHgt3yW82ae7MgxgRRfSLBM6ih",
"location": "asia-northeast1",
"projectId": "********"
},
"kind": "bigquery#queryResponse",
"rows": [...],
"schema": {...},
"totalBytesProcessed": "0",
"totalRows": "1249"
}無事にgoogleapis.bigquery.v2.jobs.queryのレスポンスが出力されていますね。
まとめ
いかがだったでしょうか。今回はGCPのWorkflowsというサービスを使ってBigQueryを操作してみました。
Workflowsは機能はシンプルですがうまく組み合わせることでコスト効率よく複雑な処理を実行できる素晴らしいサービスだと思います。
次回はWorkflowsを使用したETL基盤での日次処理について書きたいと思います。