
こんにちは!株式会社KIYONOのエンジニアです。
本日はbigqueryのコスト最適化やパフォーマンス向上の際に検討が必須のパーティショニングについて実際のハンズオンも含めて解説していきます。
想定している読者については以下のような方々です。
・bigqueryを使った分析などを最近始めた方。
・bigqueryを現在利用しているがコスト面やパフォーマンスに問題が出てきた方。
big queryにおけるパーティショニングとは??
big queryにおけるパーティショニングとは
コストの最適化とパフォーマンス向上を狙って、ある大きな一つのテーブルを細かいパーティション(仕切り)に分割することを指します。
上記のように大きい一つのテーブルを細かい仕切りを作って分割することによって、一回のクエリで読み取られるデータの量を削減することができるので
コストが削減することができ、なおかつパフォーマンスの向上にも繋がります。
具体的には
クエリでパーティショニングがかかった値に対して処理を実行すると
big queryは該当する値に対してのみ処理を行い、それ以外のパーティションに関しては処理がスキップされます。
テーブル全体をスキャンするか、該当する一部の場所に対してスキャンを実行するかの違いなのでどちらがコスト的、パフォーマンス的に優れているかは明白ですね。
概要図
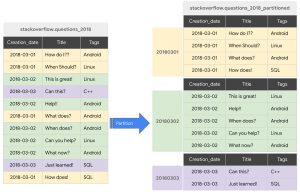
テーブル分割の仕組みについて
では、big queryにおけるパーティショニングはどのように一つのテーブルを複数のパーティションに分けるのでしょうか。
big queryにおけるテーブルの分割方法は以下のようになっています。
※こちらを理解することによって上で記載しているパーティショニングとは??の部分の理解もさらに深まると思います。
・時間単位で区切る
テーブル内に存在する[TIMESTAMP][DATE][DATETIME]型のカラムを利用してパーティションを分けます。
例えば[DATE]型のカラムには
2022-06-05このような値が格納されることになりますが、
パーティショニングを実施なかった場合では
仮に6月のデータのみ抽出した場合でも全ての月がスキャンされた上で出力されてしまいますが
月毎でパーティショニングを実施している場合は6月分のデータにのみスキャンが実施されて6月以外の全ての行に関してはスキャンがスキップされます。
・データの取り込み時間によって区切る
bigqueryがデータを取り込む際のタイムスタンプに基づいてデータを分割します。
取り込まれた時間でタイムスタンプを発行して、あとは上と時間単位で区切るだけです。
・整数IDで区切る
テーブルに含まれている整数型のカラムを利用して、テーブルを区切ります
ユーザーidのようなものが整数型で保管されている場合はこちらの方法が有効になってきます。
実際にパーティショニングされたテーブルを作ってみよう
では、いよいよパーティショニングで区切られたテーブルを作っていきましょう。
手順1:事前準備
・今回はtest_NetFlix オープンデータとして公開されていたNetflix社の過去20年分の株価に関するデータを利用します。
・test_NetFlixをGCP内の任意のcloud storage内に格納してください。
手順2:テーブル作成(今回はbigquery内のクエリでsqlを使用してテーブルを作成してみます)
・GCPコンソールよりbig queryにアクセスしてください。
・以下SQL文をクエリとして打ち込んでみてください。
└プロジェクトIDとデータセット名は任意の値に書き換えていただければと思います。
create table
xxxxx-1234565(プロジェクトID).test_dataset(任意のデータセット).partition_table(
Date DATE,
open float64,
high float64,
close float64,
adjclose float64,
low float64, volume int64,
)
PARTITION BY DATE_TRUNC(Date, MONTH)最終行のPARTITION BY TRUNC(Date,MONTH)に注目してくだいさい。
ここで、Dateカラムに対して月単位でパーティションを区切るように指示しています。
・実際に上のクエリで指定したデータセット内にpartition_table が作成さされているか確認してみましょう。
詳細欄から実際にパーティショニング要件が記載されていたら成功です!
・作成したテーブルにテストデータをインポートする(cloud shellのbqコマンドを使ってインポートします。)
cloud shellを開いて以下のbqコマンドを打ち込んでください
└データセット名とNetFlix.csvが置かれているパスは任意の場所なので書き換えてください。
bq load --skip_leading_rows=1 先ほど設定した任意にデータセット.partition_table gs://NetFlix.csvが置かれているパス
・big query内のpartition_table内にcsvの値が入ってるか確認してみましょう。
手順3:動作確認
ここまでくればあとはパーティショニングが実際に適用されてクエリ量が減っているか
確認するだけです。
①テスト用で作成したパーティショニングをしないでtest_NetFlixをインポートしたテーブルに対して
日付を指定したクエリを記載します。

②先ほど作成したパーティショニングをしたテーブルに対して同じ日時を指定してクエリを記載します。

赤色の下線を引いている部分に実行した際の結果が表示されてます。
同じtest_NetFlixに対して同じクエリを投げているのですが
①のパーティショニングをしていないテーブルの実行結果が275.35KB
②の月毎にパーティショニングをしたテーブルの実行結果が1.15KBとなっております。
これはテーブルが先ほど定義したように月毎でパーティショニングされているので
指定した月のパーティション以外は読み込んでいないためですね。
まとめ
いかがでしたか??
今回のようにパーティショニングを実施するのとしないのでは
クエリの費用に大きく影響を及ぼすことがわかりました。
分析量が増えてきてクエリの実行費用にお悩みでしたら
ぜひ一度テーブルが適切にパーティショニングされているか確認してみてださい。