こんにちは。猛暑です。KIYONOエンジニアです。
今回はイベントを起点とした一連の処理の自動化について共有したいと思います。
本記事の対象者としては以下に当てはまる方を想定しております。
- GCPのサービスを使いたい
- イベントドリブンな処理を行いたい
- 一連の処理を自動化したい
GCP上でのシンプルな処理の自動化については以前の記事に記載しておりますのでぜひご覧ください。
Eventarcについて
Eventarcは2020年10月にリリースされた比較的新しいサービスです。Google サービス、SaaS、独自のアプリからイベントを非同期的で配信できるサーバーレスなサービスです(公式ドキュメント)。
データフォーマット
システム間のデータ送受信においてデータ形式が標準化されていることは重要です。Eventarcでは数多くのイベントを管理/収集し、これらのイベントをCloudEventsに準拠したフォーマットで特定の宛先に配信することができます(公式ドキュメント Eventarcの概要)。CloudEvents は標準的な方法でイベント メタデータを記述するための仕様で、Cloud Native Computing Foundation の Serverless Working Group が管理しています。
イベント管理
サービス同士をイベントを起点に連携させたいのであれば、関数内に外部システムAPIに対するリクエスト等の処理を記述してしまえば可能なことです。一方でそれは拡張性の高い疎結合なシステム開発とは逆行しているものです。Eventarcを利用することでイベントの統合/一元管理の場を設け、イベントを利用したシステム開発を疎結合で標準化されたものにすることが可能です。
また、特定のイベントをトリガーに順序立ったワークフローを起動させたい場合には全ての処理にイベントトリガーを付与してイベントを連鎖させる必要はありません。Eventarcで管理しているトリガーに対してWorkflowsで作成したワークフローを紐付けることで、イベントを起点とする連続した処理の実行が可能となります。
今回の構成
今回は『Cloud Storageの特定のバケットにCSVがアップロードされた後、自動的にBigQueryにデータを転送する』一連の処理を作成したいと思います。
構成図は以下となっております。
![]()
処理フローは大きく3つです。
① Cloud Storageの特定のバケットにファイルをアップロード
② Eventarcが①のイベントを捕捉しWorkflowsを起動
③ WorkflowsがBigQueryへデータ移行を行う
それぞれのサービスについてセットアップを行いましょう。
各サービスの準備
Cloud Storage
テスト用にバケットとフォルダを作成します。
Workflows
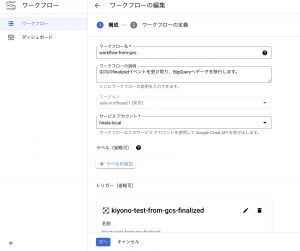
まずはワークフロー名やサービスアカウント、トリガーの設定を行います。
このトリガーとしてEventarcを選択し、トリガーの内容を設定します。設定内容は後ほど説明します。
ワークフロー名
わかりやすい名前をつけてください。
サービスアカウント
ワークフローの権限に関するアカウントとなります。今回はBigQueryへの操作とGCSへの操作が必要になるのでBigQuery管理者とストレージ管理者を付与しておきます。本番環境では必要最小限な権限となるように調整しましょう。
トリガー
Workflowsのトリガー設定からEventarcのトリガーを新規に作成することができます。
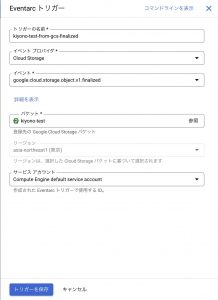
- トリガー名
- わかりやすい名前をつけてください。
- イベントプロバイダ
- Cloud Storageを選択します。
- イベント
- Cloud StorageへObjectの更新が完了した時に生成される
finalizedを選択します。
- Cloud StorageへObjectの更新が完了した時に生成される
- バケット
- 上記で作成したバケットを選択します。
処理の記述
内容については今回の記事の本質から外れているため割愛させていただきます。実務で運用される場合はエラーハンドリングとCREATE IF NOT EXISTS的な処理が必要になります。
main:
params: [event]
steps:
# 変数の宣言
- init:
assign:
- parent: ${"projects/"+sys.get_env("GOOGLE_CLOUD_PROJECT_ID")+"/locations/" + sys.get_env("GOOGLE_CLOUD_LOCATION")}
- destinationDataset: {{BigQueryのデータセット名}}
- destinationTable: {{BigQueryのデータ移行先テーブル名}}
# Eventarcから受け取ったイベントを確認する
- log_event:
call: sys.log
args:
text: ${event}
severity: INFO
# データ転送先のテーブルを作成する
- create_table:
call: googleapis.bigquery.v2.tables.insert
args:
datasetId: ${destinationDataset}
projectId: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")}
body:
schema:
fields:
- {name: "order_id", type: STRING}
- {name: "return" , type: STRING}
tableReference:
datasetId: ${destinationDataset}
projectId: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")}
tableId: ${destinationTable}
# データ転送に関する設定を作成する
# paramsの設定はこちらのドキュメントを参照(https://cloud.google.com/bigquery-transfer/docs/cloud-storage-transfer#bq)
- create_transfer_config:
call: googleapis.bigquerydatatransfer.v1.projects.locations.transferConfigs.create
args:
parent: ${parent}
body:
dataRefreshWindowDays: 0
dataSourceId: "google_cloud_storage"
destinationDatasetId: ${destinationDataset}
displayName: "from-workflows"
scheduleOptions:
disableAutoScheduling: true
params:
data_path_template: ${"gs://" + event.data.bucket + "/" + event.data.name}
destination_table_name_template: ${destinationTable}
file_format: "CSV"
skip_leading_rows: "1"
result: configResult
# データ転送を実行する
- run_data_transfer:
call: googleapis.bigquerydatatransfer.v1.projects.locations.transferConfigs.startManualRuns
args:
parent: ${configResult.name}
body:
requestedRunTime: ${time.format(sys.now())}
result: dataTransferResult
# ログを確認する
- final:
call: sys.log
args:
text: ${dataTransferResult}
severity: INFO実行
さあ実際に動かしてみましょう。今回は簡単のために2列のデータを使用します。
今回作成したテスト用のCloud Storageバケットへアップロードしましょう。
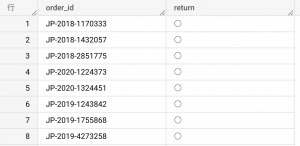
使用したデータ

GCSへの出力
うまく実行されるとログに「成功」の文字が記載されます。
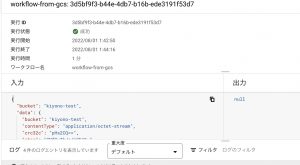
BigQuery側にもデータ転送の設定が作成されていますね。
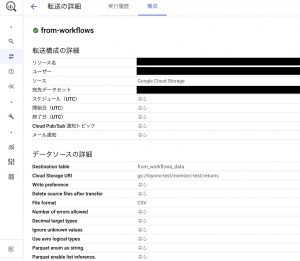
BigQueryにもデータがあることを確認できました。
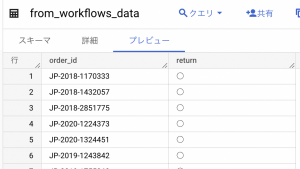
GCSへアップロード→データ転送→BigQueryの処理を自動化できました!
最後に
いかがだったでしょうか。データ分析基盤開発ではリアルタイムな処理は多いですがイベントを起点とした一連の処理の自動化はなかなか使う機会はありませんが、社内の業務効率化やアプリケーション開発では使う機会があるかと思います。メッセージのやり取りが重要な場合はpubsubを使った処理が採用されますが、単にイベントをトリガーとした処理を行いたい場合はEventarcを使ってみてはどうでしょうか。
今回の記事ではトリガーの宛先としてWorkflowsを使っているため簡素な作りになっていますが、宛先にCloud Runを使用することでよりリッチな処理を実装することも可能です。
その他気になることがございましたら、是非下のフォームよりお問い合わせください!