
こんにちは、KIYONOエンジニアの田代です。
Geminiのマルチモーダル機能


画像理解: 画像の内容を理解し、オブジェクトの検出、画像の分類、キャプション生成などが可能。文書処理 文書の内容を理解し、テキストの抽出、翻訳、要約などが可能。: 動画理解 動画の内容を理解し、アクションの認識、シーンの分類、動画からの質問応答などが可能。:
なぜマルチモーダル機能が重要なのか?

ユースケース
画像 → ウェブページ: 画像からウェブページを生成
手書きのWebページのイメージをもとにWebページを生成するデモの様子
画像理解: 画像の内容に基づいて質問に答えたり、キャプションを生成したりする機能。


画像をもとに都市の景観における特定のランドマークを特定し、その歴史的背景について詳細な情報をGeminiから返してもらう様子
- 文書処理:手書き文字の認識や、複雑な数式の分析など、高度な文書処理タスク。

手書きの文書や図形を文字起こしする様子

商品パッケージの画像をHTMLテーブルに変換する様子
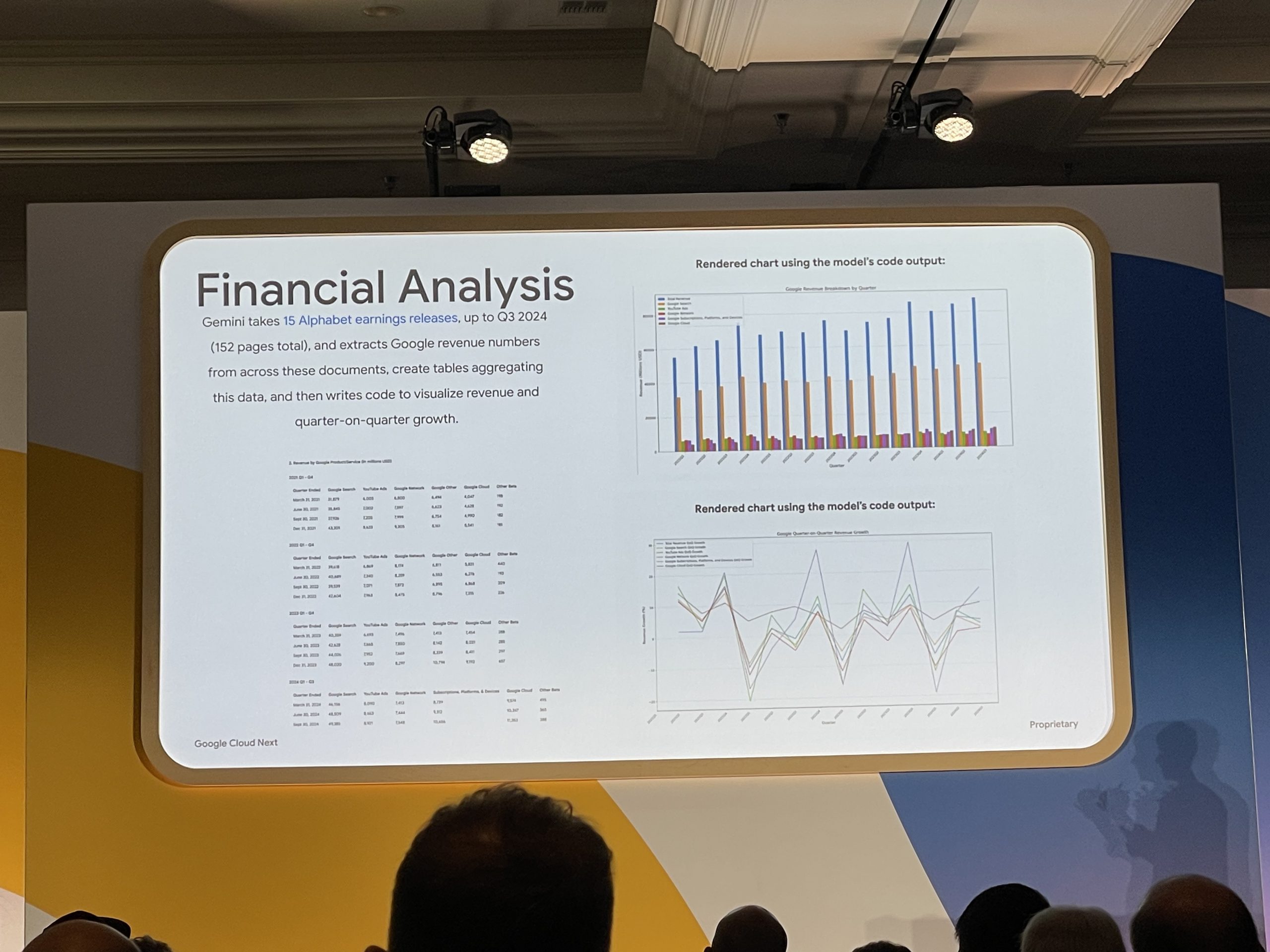
Alphabet(Googleの親会社)の決算報告書を処理し表やグラフにまとめる様子
- 動画理解:動画の内容に基づいて質問に答えたり、要約を生成したりする機能。

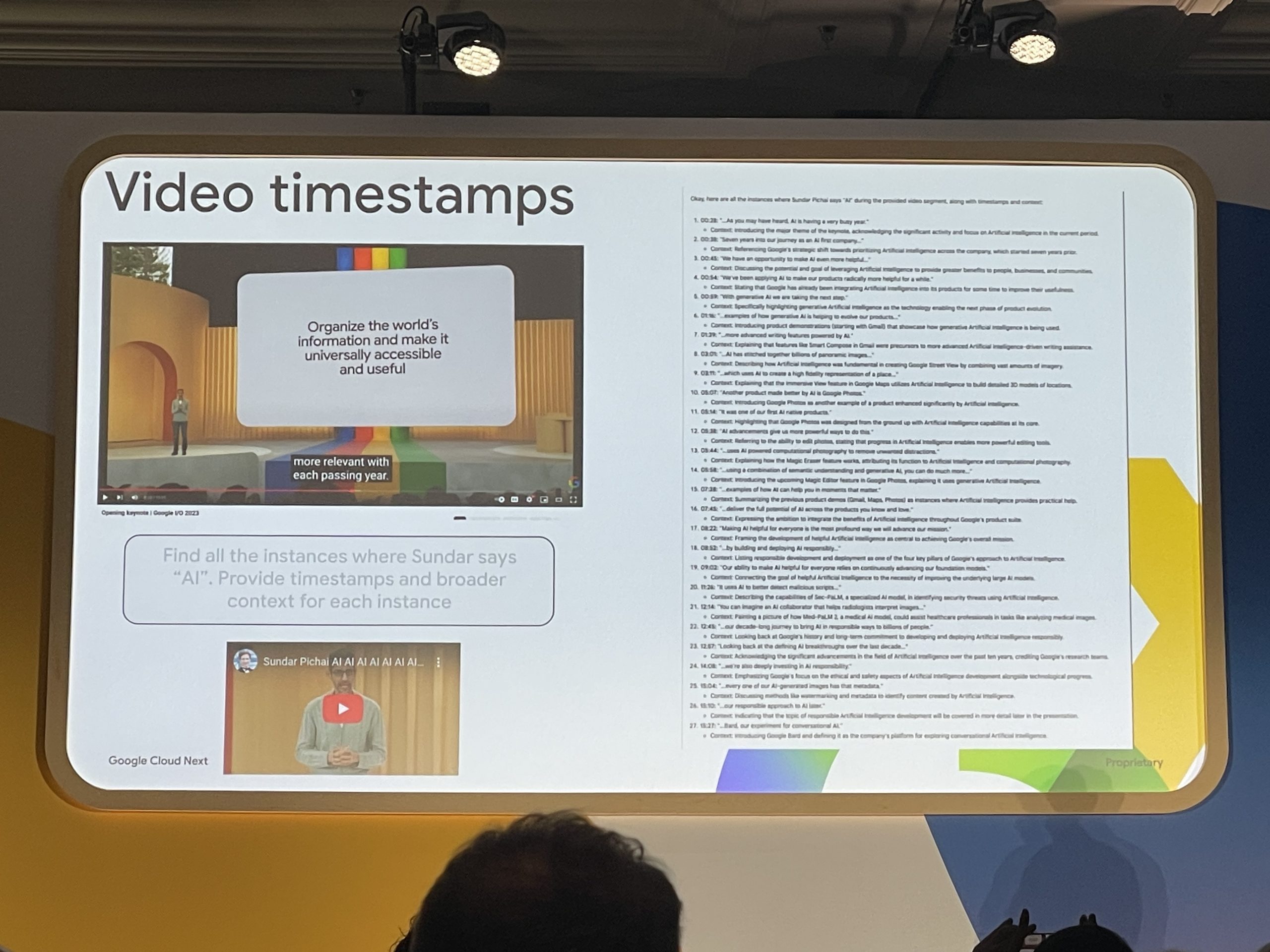
プレゼン動画を分析し「AI」について言及したインスタンスを特定してタイプスタンプに書き起こす様子

物理学の衝突に関する教育ビデオを解析し、シミュレーションや状態相関、結果表などを自動生成する様子
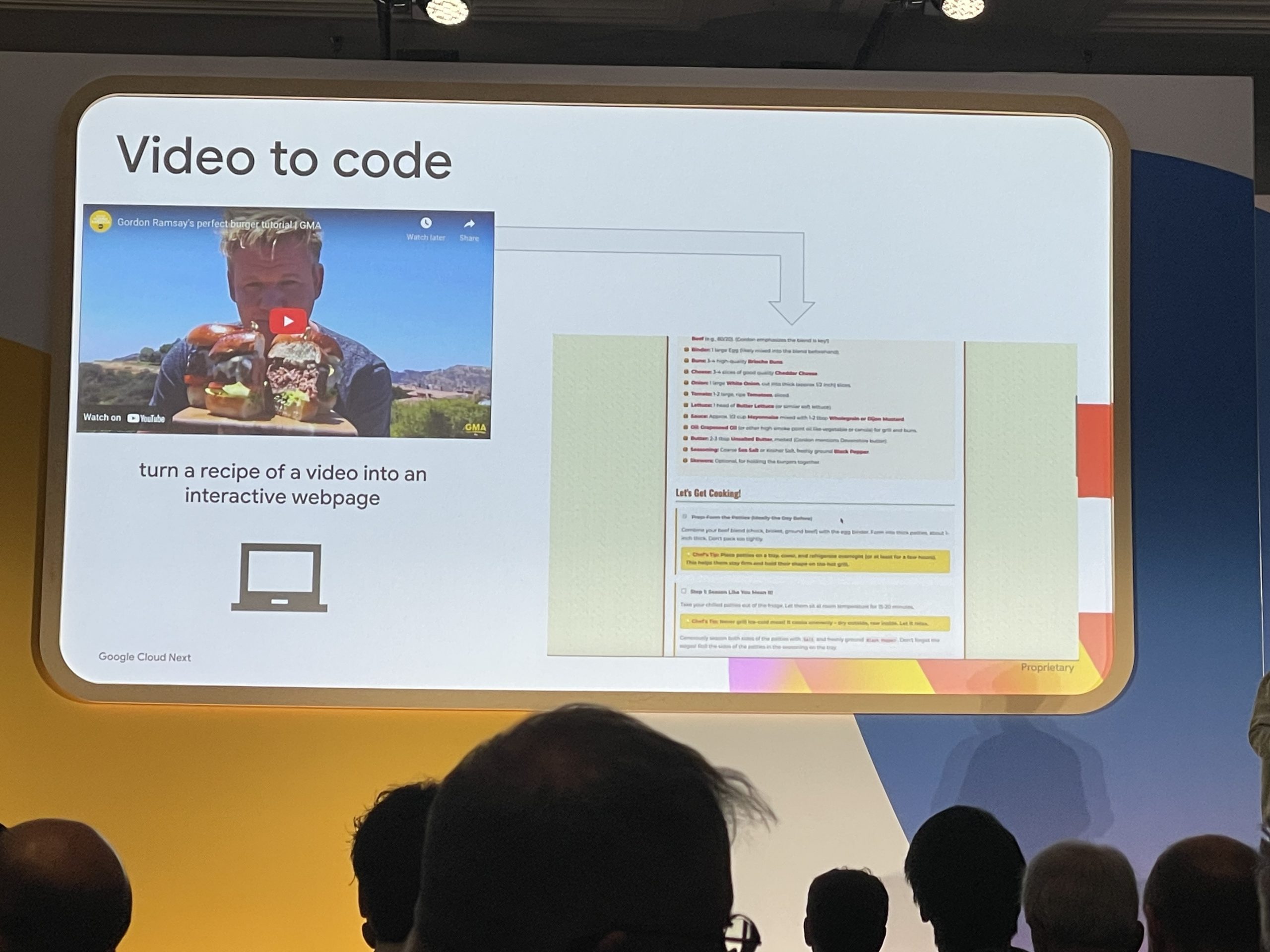
料理のビデオからレシピーのコードを抽出しWebページを自動生成する様子

開発者向け情報
API
Geminiのマルチモーダル機能は API経由で利用可能です。開発者は、APIを使用して独自のアプリケーションに Geminiの機能を統合できます。
Google AI Studio
Google AI Studioは、GeminiをはじめとするGoogleのAIモデルを試すことができるプラットフォームです。
Gemini 2.5のパフォーマンス
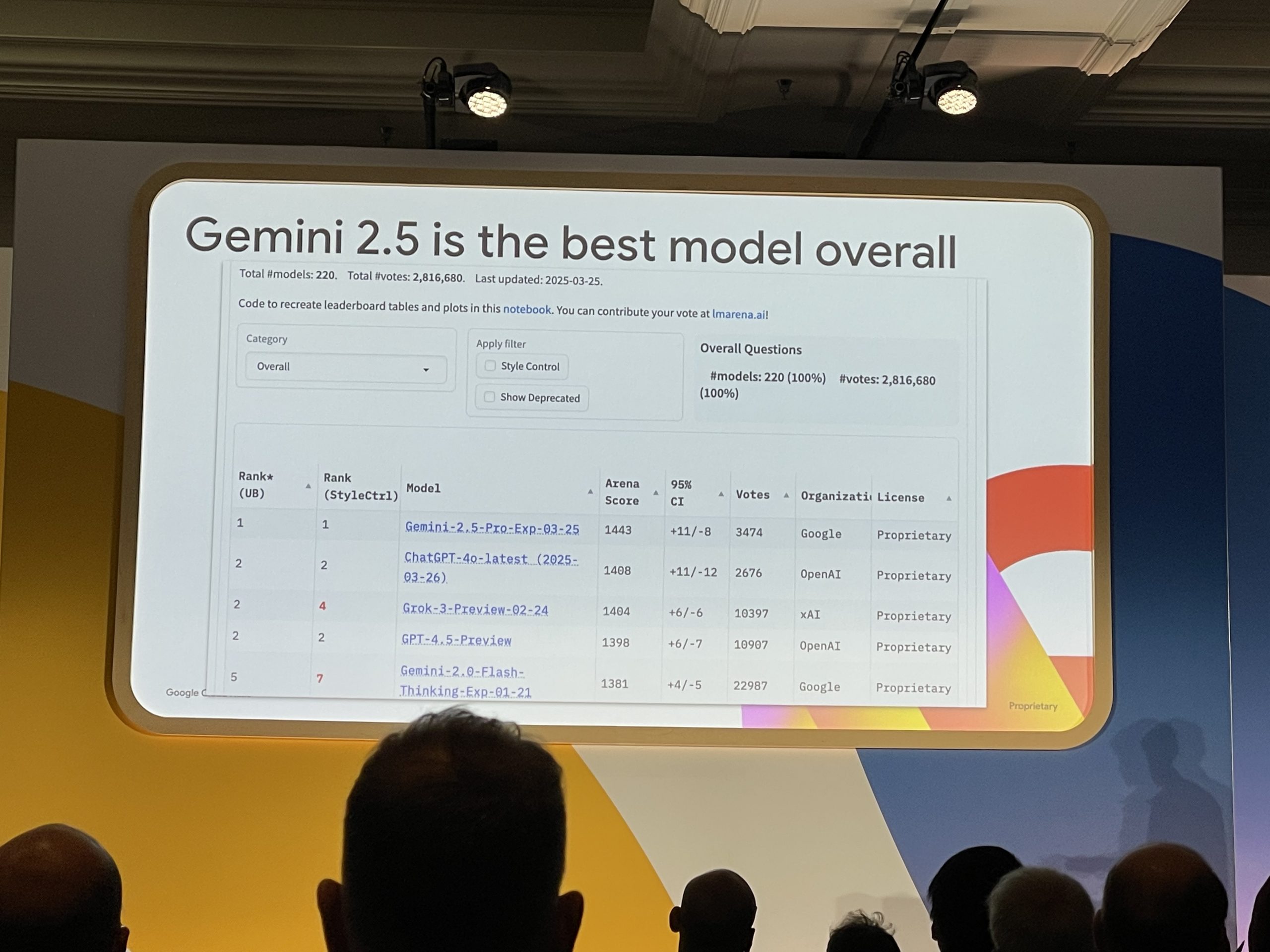
特に、マルチモーダルタスクにおいては、他のモデルを大きく引き離す性能を達成しています。
質疑応答
質問: Geminiは、どのような種類の動画を処理できますか?動画の長さや形式に制限はありますか?回答: Geminiは、最大1時間の長さの動画を処理できます。また、MP4や YouTubeリンクなど、様々な形式の動画に対応しています。ファイルサイズの上限は20MBです。それ以上のサイズの動画の場合は、Drive経由でアップロードできます。質問: マルチモーダルモデルは、従来の単一モダリティのモデルと比べてどのような利点がありますか?回答: マルチモーダルモデルは、複数の種類のデータを統合的に処理できるため、より高度なタスクをこなすことができます。例えば、画像の内容を説明するキャプションを生成したり、動画の内容に基づいて質問に答えたりすることが可能です。質問: GeminiのAPI は、どのようなプログラミング言語で利用できますか?回答: Gemini のAPIは、様々なプログラミング言語で利用できます。詳細は、Google Cloudのドキュメントをご覧ください。質問: Geminiの料金体系はどのようになっていますか?回答: Geminiの料金は、利用状況に応じて変動します。詳細については、Google Cloudの営業担当者にお問い合わせください。

コメント