
概要
こんにちはKIYONOのエンジニアの西園です。
今回はBigtableのアーキテクチャについて簡単に解説してみたのでご覧ください。
Bigtableとは?
Bigtableとは、端的に言うと大量のデータをリアルタイムで処理することに優れているNoSQLのデータベースです。
つまりポイントは下記3つです。
- 大量データ処理
- リアルタイム処理
- NoSQLデータベース
これでほぼBigtableをわかったも同然ですね。(はい、冗談です。。。)
気を取り直して、使用用途は下記のようなものがあります。
- 時系列データ。複数のサーバーにおける時間の経過に伴う CPU とメモリの使用状況など。
- マーケティング データ。購入履歴やお客様の好みなど。
- 金融データ。取引履歴、株価、外国為替相場など。
- IoT(モノのインターネット)データ。電力量計と家庭電化製品からの使用状況レポートなど。
- グラフデータ。ユーザー間の接続状況に関する情報など。
引用:公式ドキュメント
これだけ見ると「へ〜そうなんだ」で終わります。しかしKIYONOのエンジニアはここから一歩へ。
ということでもっと読者のみなさんがイメージしやすい事例を探してきました!
みなさん知っていますか?
調べたい言葉を入れると適切な情報を提供してくれる代物を。
そう!
Google検索エンジンです!!
実はGoogleの検索エンジンにもBigtableが使用されています。
何十億ものユーザーから大量に送られてくるリクエストをリアルタイムで処理をして結果を返さないといけないので、
まさにBigtableの特性が非常にマッチしています。
特徴
Bigtableの特徴は大きく分けて3つあります
- 高スループット → 単位時間あたりに処理できるデータ量が多い
- 低レイテンシ → 通信の遅延時間が少ない
- フルマネージド → 特に管理の手間がいらない
アーキテクチャ
Bigtableのアーキテクチャはそこまで複雑ではありません。
抑えるべき要点は下記のたったの3つです
- クラスタ
- ノード
- タブレット
もっと簡単に表すと
- クラスタ = 作業スペース
- ノード = 作業する人たち
- タブレット = 作業に必要なものを収める倉庫
正確にはもっと細かいものも含まれていますが、この3つさえ理解していれば大丈夫です。
アーキテクチャ図
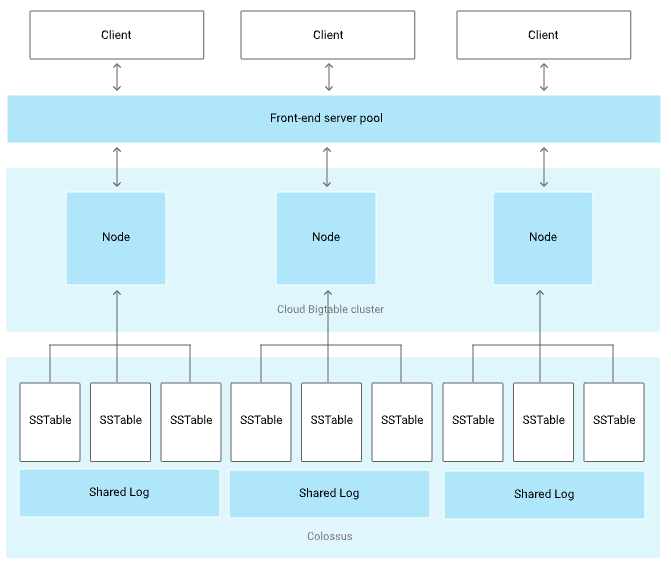
引用:公式ドキュメント
クラスタ
クラスタとはアーキテクチャ図の中間に位置している部分のことで、ここは主にノード(後ほど解説します。)を配置する領域になります。
クラスタ自体が何か処理を行ったりということはしません。先ほど記載した通り単なる作業場です
大きな特徴としてはゾーンに1つのみ配置できるということです。
ノード
ノードはクラスタ内で処理を担ってくれるコンピュータリソースです。つまり作業する人です。
ここは、書き込みや読み込みなどが発生した場合に一生懸命に働いてくれます。
また各ノードは特定のタブレットと紐づいていて、その紐づいたタブレットに対して書き込みや読み込みの処理を行います。
設定によっては負荷に応じて自動的に数を増加させたり、管理の手間を省くこともできます。
タブレット
タブレットはアーキテクチャ図の下部に位置するSSTableと記載されている部分です。
SSTableとはデータの格納方式のことでここではあまり重要ではないので割愛します。
ここはデータの倉庫です。ここからデータを読み込んだり、ここにデータを書き込んだりします。
Bigtableは基本的に1つのテーブルにデータを集約して使用します。その集約したテーブルがタブレットとして分割されて各ノードと紐づいています。
データ構造
次にデータ構造について説明していきます。
Bigtableは基本的に下記の3つで構成されています。
- 行キー(Row key)
- 列ファミリー(Column family)
- 列(Column)
- セル
データ構造は下記のような形です。

引用:公式ドキュメント
行キー(Row key)
基本的にこの行キーを使用してデータを探索します。行キーはスキーマを設計する上でパフォーマンスの観点から非常に重要となります。
列ファミリー(Column family)
列ファミリーとは関連する列をグループ化するものです。
列(Column)
列はカラム名のことです。たとえば、user_idやageなど様々です。
セル
セルは行と列が交わる個々のデータが格納されるところです。
特徴的なのは値を更新した際に古いデータは削除されるのではなく、タイムスタンプによりセル内で保存される点です。
つまり更新すればするほどセル内にデータが溜まっていきます。
これを解消するためにガベージコレクションを利用します。
ガベージコレクション
ガベージコレクションとはセル内に保存されている古いデータを削除することができる設定です。
ガベージコレクションポリシーで詳細を設定することができます。
削除方式は2種類下記の2種類です
- 期限切れ値の設定 = タイムスタンプベースで削除する方式
- ex) 何日以前のデータを削除
- バージョン数 = データ保持数を決めることで、削除する方式
- ex) 保持数を5個に設定した場合、順次溢れた古いデータは削除
特徴
Bigtableのデータ構造は行指向です。つまりデータをスキャンする際に行単位でスキャンします。
その構造から基本的には横長のテーブルにすることでスキャン効率が良くなります。
しかし、すべてが横長のテーブルにすればいいわけではありません。
たとえば下記の時系列データのように何か特定の値をタイムスタンプごとに格納する場合、無限に横長にデータが増えてしまいます。(※テーブルは簡易的に列ファミリーを省略して記載しています。)
| 行キー\列 | 2022-0101-1200 | 2022-0102-1201 | 2022-0103-1202 | ・・・ |
| tokyo#temperature | 14 | 8 | 8 | ・・・ |
ここで抑えとくべきポイントはBigtableの一行のデータ量は100MB以下にすることがパフォーマンスの観点から望ましいということです。(最大は256MB)
したがって例に挙げたような時系列データのように何か特定の値を時間ごとに格納する場合は下記のように縦長に設計した方が良いです。
| 行キー\列 | temperature |
| tokyo#2022-0101-1200 | 14 |
| tokyo#2022-0102-1201 | 8 |
| tokyo#2022-0103-1202 | 8 |
| ・ | ・ |
| ・ | ・ |
上記のように設計することで一行のデータ量は100MB以下という用件を満たすことができるのでパフォーマンスの低下を防ぐことができます。
またデータの並び順には2つ大きな特徴があります。
行キーの辞書順にデータが並ぶ列ファミリーの中で列は辞書順に並ぶ
辞書順に並ぶという特徴から行キーの設定次第でパフォーマンスに大きく影響します。
スキーマ設計
いよいよ来ましたスキーマ設計!Bigtableにおいてはパフォーマンスの観点からこのスキーマ設計が非常に肝になります。
そもそもスキーマ設計って何やねんという人のために軽く解説します。
スキーマ設計とは
端的に表現すると、データベースにおけるデータ構造を設計することです。
Bigtableでいうところの先程記載した行キー、列ファミリー、列にどういった値を設定するかを決めることです。
スキーマ設計の流れ
まずスキーマを設計するときの流れが公式ドキュメントに記載されています。簡単に紹介します。
流れとしては下記のように実施していきます。
デザインの決定 → テストの実施 → 調査 → デザインの再定義 → テスト → ・・・
この流れを繰り返し、適切なスキーマ設計を実現していきます。
それではそれぞれいったい何をやるのかっていうところを解説していきます。
1. デザインの決定
最初は初期スキーマを決めます。
つまり、行キー、列ファミリー、列にどういった値を設定するのかを暫定的に決めます。
なおここでは後ほど記載する避けるべき行キー設計に基づいて設計します。
2. テストの実施
設計したスキーマによってパフォーマンスを測定します。
具体的には、下記のように行っていきます。
1. 設計したスキーマを元にテーブルを作成
2. 30GB以上のデータを用意してテーブルに読み込む
3. 高負荷テストを数分間実施
4. 読み取りと書き込みについて1時間のシミュレーションを実施
5. Key VisualizerやCloud Monitoringを使用してシミュレーション結果を確認
<備考>
- Key Visualizer → 処理が集中している行がどこなのかを特定できる
- Cloud Monitoring → Bigtableでは、どこのノードのCPU使用率などを確認できる
3. 調査
最後にテストの結果を受けてスキーマを再設計します。この時にテストで使用したKey Visualizerで確認した指標を元に実装していきます。
避けるべき行キーの設計
Bigtableにおける行キー設計には避けるべき事柄がいくつかあります。
大きく考慮しなければならないことが2つあります。
- 連続した行に書き込みを行わない
- 1つの行を頻繁に更新しない
具体的な設計で注意しなければならない事例を1つをご紹介します。
1. 先頭がタイムスタンプの行キーしない
2022-0101-1200のようなタイムスタンプを行キーの先頭に持っていくとパフォーマンスが低下してしまいます。
例としては下記のような行キー設計のことを言います。
| 行キー\列 | temperature |
| 2022-0101-1200#tokyo | 14 |
| 2022-0102-1201#tokyo | 8 |
| 2022-0103-1202#tokyo | 8 |
| ・ | ・ |
| ・ | ・ |
ではなぜパフォーマンスが低下するのか。
ポイントは下記の2つです。
- データは行キーの辞書順に並ぶ
- クラスタ内の各ノードは特定のタブレットに紐づいている
Bigtableのデータは基本的に辞書順に並ぶのでタイムスタンプが先頭の行キー設計を採用すると
書き込まれたデータが全て連続した行で書き込まれてしまいます。つまり特定のタブレットに書き込みが集中します。
そしてノードは特定のタブレットに紐づいているので、あるノードに処理が集中する状況になります。
そうなると極端な話、下記の図のように特定のノードのみ稼働してしまって他のノードがほとんど稼働しない状況が生まれてしまいます。
データ量が少なければ下記のような状況でもパフォーマンスにそれほど影響を与えないかもしれませんが、
基本的にBigtableは大量のデータをリアルタイムで処理する用途で用いられますのでこういった状況は考慮しなければなりません。
簡易アーキテクチャ図
もしその他にも事例を知りたい場合は公式ドキュメントを参照してください。
まとめ
いかがでしたでしょうか。
KIYONOのエンジニアはデータ分析基盤の構築なども行っていますので、
データ基盤を構築したいなど要望がありましたらぜひお問い合わせください!