
こんにちは! KIYONOエンジニアです。
今回は、ビッグデータ処理のためのフレイムワークとして活躍してきた、Hadoop、Sparkについて基礎的な部分の解説と、昨今のオンプレミス環境からクラウド環境への移行需要を満たすGCPサービス( Dataproc・Dataflow) の紹介していきたいと思います。
対象読者様としては、これから学習される方、すでに自社でHadoopやSpark環境を導入しているけれど改めて理解を深めたい方、ビッグデータの処理基盤をオンプレミス環境からクラウド環境への移行を検討されている方、DataprocやDataflowを活用してみたいけど導入の背景を知りたい方、なんとなくビッグデータの世界に触れてみたい方など。
Hadoop、Spark誕生の経緯から、仕組みの概要理解、クラウドへの移行までざっくりと解説しておりますので、ご一読読いただけると幸いです。それでは、さっそく、Hadoop、Spark誕生の背景から解説をしていきます。
Hadoop誕生の経緯
POINT– データ分析の処理に手間と時間がかかる –
2000代初頭当時、インターネットの発展や企業の扱うデータが膨大で複雑になりつつあった中、「大量のデータを保存する」 「計算処理をする」 ことが課題となっていました。大量のデータを処理をしようにも、効率的に実行する仕組みがなかったため、技術的な限界に直面していました。
2003年、Webクローラーを開発した、オープンソースソフトウェア(OSS)のパイオニア「Apache Nutch」プロジェクトが発足します。ただ、当プロジェクトのWebクローラーは、計算処理の並列化に苦労していました。「Nutch」は1台のマシン上ではうまく機能しましたが、何百万ものWebページをの処理(Webスケール)は、困難な作業でだったそうです。
そんな要求を叶えるべく、Nutchプロジェクトの主要メンバーにより、Hadoopのプロジェクトが発足し、開発が開始しました。
Hadoop誕生
たとえば、世界中のサイトを集めて検索エンジンを作るためには、膨大なデータを保存しておけるストレージと、そのデータを次々と処理し続けられる仕組みが必要でした。そのために、何千何万ものコンピュータが利用され、それを管理するためのソフトウェアがHadoopです。
HadoopはGoogleの「Google File System」論文、「MapReduce」論文の影響を受け、2006年にオープンソースソフトウェア(OSS)としてリリースされました。
Hadoopとは
Hadoopとは多数のコンピュータで大量のデータを並列分散処理するためのフレイムワーク ( OSS )です。
NoSQLの技術と並び、ビッグデータの代名詞と言われた技術でした。
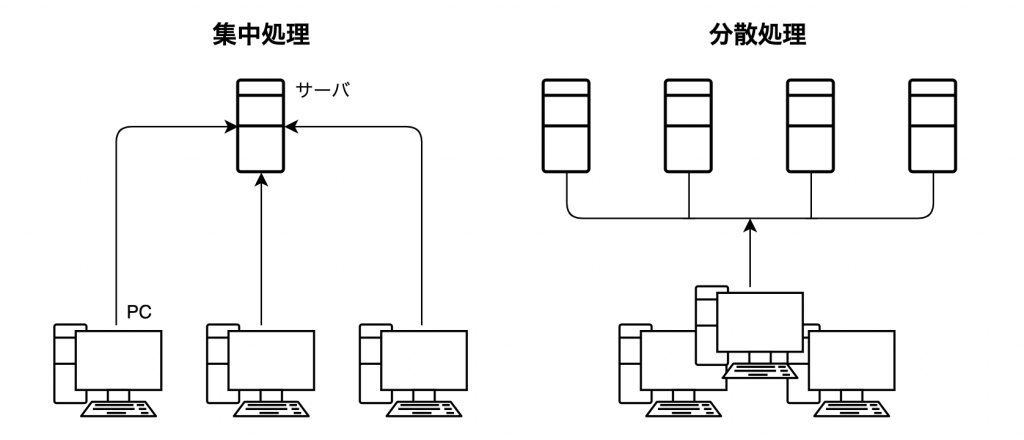
POINT – 分散処理って ? –
ひとつの計算処理をネットワークで接続した複数のコンピュータで同時並列で処理すること
※ 集中処理・・・旧来の一つのサーバで処理を行う形態
下図は一般的なイメージです
Hadoopの仕組み
- Hadoopの主な構成要素
-
- HDFS・・・・・・データを貯める(ストレージ・ディスク)
- MapReduce・・・ データの処理をする ← 機械学習など高反復・複雑な処理になると非効率で低速度に…
- YARN・・・・・・ データ処理のリソースを管理する ( 今回は説明割愛 )
- 主な活用言語:Java
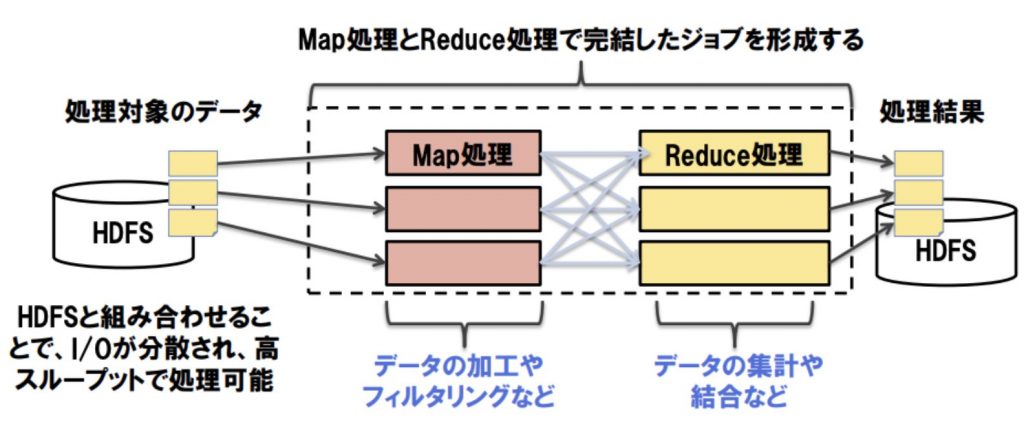
画像 : [ NTT DATA様 – 学んで動かす!Sparkのキホン ] より引用
-
Hadoopは比較的シンプルな構成のビッグデータ処理において大活躍しました。
ただ、処理部分のMapReduceなど、弱点があり、すべてが完璧なソフトウェアというわけではありませんでした。
Sparkの誕生
2014年、Hadoop出身メンバーによる別プロジェクトとして開発が行われ、 Apache Spark リリースされました。
-
-
- Hadoopの処理部分 ( MapRedece ) の欠点に目をつけた分散処理のフレイムワーク ( OSS )
- SparkはHadoopより効率の良いデータ処理を実現
- 主な仕組み・特徴
- データ処理にキャッシュ・メモリを活用する( I/Oが減少 )
- バッチ処理、機械学習処理にも対応
- Scala / Java / Python/R をメインに対応 (ライブラリによってより、様々な言語を活用可能)
-
Sparkはキャッシュ・メモリなどHadoopの処理部分の抽象化技術により、処理スピード向上、効率化を実現しました。
これまで難しかった、高反復で複雑な処理にも対応することで、バッチ処理を始め機械学習やETL処理へ活用されていくこととなりました。
POINT – Hadoop + Spark –
-
-
- 既にHadoop環境がある場合、Sparkは導入が簡単
- SparkはHadoopを置き換えるものではなく、HadoopのMapRedeceを置き換える存在
- Hadoopとの組み合わせのうちの、メジャーな一例
-
→ Hadoop + Spark の合わせ技 がビックデータ処理の構成でメジャーとなりました。
時系列
| 時期 | イベント |
| 2003 | Hadoopの前身 Nutchプロジェクト発足 |
| — | GoogleからGoogle File System 論文発表 |
| 2004 | GoogleからMapReduce 論文発表 |
| 2006 | Hadoopの初期版 リリース |
| 2011 | Apache Hadoop 1.0.0 リリース |
| 2014 | Apache Spark 1.0.0 リリース |
| 2015 | Google Cloud Dataflow リリース |
| 2016 | Google Cloud Dataproc リリース |
オンプレミスからクラウドへ
Hadoop、Sparkはオンプレミス環境から活用され始めた経緯があり、現在も複数の自社サーバを所有する企業などで運用されていると考えられます。
ただ、昨今の技術進歩により、クラウド環境に対応したビッグデータの処理サービスが各社より提供されております。
以下、ビッグデータ処理サービスを提供するプロバイダー
-
-
- オンプレ型 Hadoop :Apache Hadoop、Cloudera、MapR …
- Cloud型 Hadoop :Google Dataproc、Amazon EMR、Azure HDInsight …
-
Dataproc
POINTHadoop、Spark環境をクラウドに移行したい → Google Dataproc

これまで説明してきた、既存のHadoop、Spark環境を所持している場合には、Dataprocの活用がクラウドシフトに最適な選択肢となります。
技術:Hadoop、Sparkを踏襲
- オンプレミスでApacheSparkまたはHadoopに多額の投資をしていて、クラウドへの移行を検討している場合
- ハイブリッドクラウドを検討していて、プライベート/マルチクラウド環境全体での移植性が必要な場合
- Devops開発のリソースがある場合・・・開発担当者とインフラ運用者の連携が充分に取れている場合(インフラ環境の設定に慣れていえる場合)
Dataflow
POINT新規にビッグデータ処理基盤をクラウドで → Google Dataflow

これまで、Hadoop、Spark環境からクラウド環境への移行をご説明しましたが、参考に、新規導入する場合についてもご紹介します。
Google Dataflowは複雑なインフラ構築の設定を気にする必要のないサーバレスサービスであり、新規にビッグデータ処理基盤をクラウドに構築したい場合に最適なクラウドサービスです。
技術: Apache Beam を使用
- ビッグデータのETLパイプライン・機械学習処理・バッチ処理の基盤として、新規にクラウド環境を活用したい場合
- フルマネージドのサーバーレスサービスを活用し、余計な設定面に時間を割きたくない場合
Dataproc ? or Dataflow ?

画像: https://cloud.google.com/dataproc/#fast–scalable-data-processing より引用
以上、HadoopとSparkの概要から、クラウド移行までのご紹介でした。
今回は導入理解を目指しましたが、より詳しく知りたい方のために、参考書籍・サイトを以下でご紹介しております。
拙い記事ですが、読者の皆様の理解に少しでも貢献できていましたら幸いです。
参考書籍・サイト
西田 圭介 (著) 『ビッグデータを支える技術』-ラップトップ1台で学ぶデータ基盤のしくみ ( WEB+DB PRESS plus )
Googleドキュメント – Dataproc
Googleドキュメント – Dataflow
Googleドキュメント – Apache HadoopをDataprocへ移行
teruuuのブログ様 – Hadoopについて調べてクラスタを構築してみた
クリエーションライン株式会社様 – Hadoop製品の特徴について
NTT DATA様 – 学んで動かす!Sparkのキホン
jayendrapatil.com – Google Cloud Dataflow vs Dataproc